slick-doc-ja 3.0
Slick 3.0 documentationの日本語訳です。
- 編集先: GitHub - krrrr38/slick-doc-ja
- 連絡先: @krrrr38
他のバージョンのドキュメント
- Slick 1.0 翻訳
- Slick 2.0 翻訳
- Slick 3.0 翻訳
API Documentation (scaladoc)
- Slick Core (slick)
- TestKit (slick-testkit)
- Code Generator (slick-codegen)
- Direct Embedding (slick-direct) (Deprecated)
- Slick Extensions (slick-extensions)
Slick 3.0.0 documentation - 01 Introduction
Permalink to Introduction — Slick 3.0.0 documentation
導入
What is Slick
Slick (“Scala Language-Integrated Connection Kit”)はTypesafe社によってリレーショナルデータベースを簡単に扱うための、ScalaのFRM (Functional Relational Mapping)ライブラリである。まるでScalaのコレクションを扱うかのような操作でデータベースにアクセスし、データを操作出来る。SQLを直接扱うことも可能である。PlayやAkkaを基にしたリアクティブアプリケーションに完璧にフィットするよう、データベースへの処理は非同期に実行される。
val limit = 10.0
// クエリはこのように書く事が出来る
( for( c <- coffees; if c.price < limit ) yield c.name ).result
// こちらのSQLと等しい: select COF_NAME from COFFEES where PRICE < 10.0
SQLを直接書くのに比べ、Scalaを通してSQLを発行すると、コンパイル時により良いクエリを型安全に提供する事が出来る。Slickは独自のクエリコンパイラを用いて、データベースに対するクエリを発行する。
すぐにSlickを試したいのなら、Typesafe Activatorを利用して、Hello Slick templateを試してみると良い。こちらを読むと、Slickがコードを生成したり出来る、サポートされたデータベースの概要が分かる。
Functional Relational Mapping
関数型言語を用いるプログラマは長い間、リレーショナルデータベースを用いる際に、Object-RelationalとObject-Mathのミスマッチに悩まされてきた。Slickの持つ新たなFRMのパラダイムは、Scalaを通して、疎結合で最小限の設定のみで、リレーショナルデータベースへ接続する複雑さを抽象化する事を可能にした。
我々はリレーショナルモデルと闘おうとはしていない。ただ、関数型のパラダイムを通してリレーショナルモデルを包み込んだのだ。オブジェクトモデルとデータベースモデルのギャップに対してのブリッジを作ることで、Scala側へデータベースモデルを持ち込み、結果としてエンジニアはSQLを書く必要がなくなったのである。
class Coffees(tag: Tag) extends Table[(String, Double)](tag, "COFFEES") {
def name = column[String]("COF_NAME", O.PrimaryKey)
def price = column[Double]("PRICE")
def * = (name, price)
}
val coffees = TableQuery[Coffees]
Slickはデータベースに関する事柄を直接Scala側へと統合させる。そして、メモリ上のデータを操作するのと同じように、従来のScalaのクラスやコレクションを扱うかのように、クエリを発行して外部のデータを操作するのである。
// nameカラムのみを取り出すクエリ (select NAME from COFFEES)
coffees.map(_.name)
...
// 10.0未満のpriceで絞り込んだクエリ (select * from COFFEES where PRICE < 10.0)
coffees.filter(_.price < 10.0)
これは、いつデータベースにアクセスしただとか、どのデータが変更されたかなどといったアクションを全てコントロール出来る。SlickのFRMに含まれる、言語に統合されたクエリモデルは、MicrosoftのLINQやEricssonのMnesiaの早期のコンセプトに影響を受けている。
関数型言語に対するSlickのFRMなアプローチには、以下のようなメリットが含まれている。
- 事前最適化による効率化
ORMとは異なりFRMは、より効率的にデータベースへ接続を行う。これは、データベースとの接続を最適化する機能を備えているためであり、さらにFRMを用いる事であなたは柔軟にその機能を利用出来る。より高速化されたアプリを作るためには、FRMはORMに比べ役に立つ。
- 型安全性を用いた、迷惑なトラブルシューティングとの決別
FRMは型安全にデータベースのクエリを作成する事が出来る。今まで型のないただの文字列だけでエラーを探してきたデベロッパーにとっても、今や自動的にコンパイラがエラーを見つけてきてくれるのだ。
priceカラムのタイポがある場合には、コンパイラはこんな感じであなたにエラーを知らせてくれる。
GettingStartedOverview.scala:89: value prices is not a member of com.typesafe.slick.docs.GettingStartedOverview.Coffees
coffees.map(_.prices).result
^
他にも、こんな型エラーを知らせてくれる。
GettingStartedOverview.scala:89: type mismatch;
found : slick.driver.H2Driver.StreamingDriverAction[Seq[String],String,slick.dbio.Effect.Read]
(which expands to) slick.profile.FixedSqlStreamingAction[Seq[String],String,slick.dbio.Effect.Read]
required: slick.dbio.DBIOAction[Seq[Double],slick.dbio.NoStream,Nothing]
coffees.map(_.name).result
^
- クエリを作成するための、より生産性のある合成しやすいモデルの提供
FRMはクエリを作成するための合成可能なモデルをサポートしている。これはクエリを作る際に用いるいくつかのピースを合成するのに、非常に自然なモデルになっている。さらにこのようなモデルは、コード内で再利用もしやすい。
// priceが10未満で、name順にソートしたcoffeeの名前のみ取り出すクエリを作る
coffees.filter(_.price < 10.0).sortBy(_.name).map(_.name)
// select name from COFFEES where PRICE < 10.0 order by NAME
Reactive Applications
非同期を中心にデザインされたアプリケーションや、Reactive Manifestoに従って作られたアプリケーションにとって、Slickは非常に使いやすいようになっている。一般的に用いられている処理をブロックするシンプルなデータベースAPIとは異なり、Slickは以下の事をあなたに提供してくれる。
- I/OとCPUに処理が集中するコードが綺麗に分割されている: I/O処理が分離されていることで、バックグラウンドでI/O処理を待っている間にアプリケーションはCPUに処理が集中する処理を、メインスレッドで上手く動かす事が出来る。
- 即応性: データベースがあなたのアプリケーションを支えきれなくなった時、Slickは(状況を悪化させるような)必要以上のスレッドを作ったりはしないし、なんらかのI/O処理をロックしたりもしない。背圧はデータベースI/Oアクションのためのキューを通して効率的に管理され、少ないリソースに対してはリクエストを制限し、もし限界に達したならば即座に失敗させる。
- 非同期ストリーミングのための、Reactive Streams
- データベースリソースの効率的な利用: Slickはあなたのデータベースサーバの並列度(同時にアクティブになっているジョブの数)やリソースの利用度(現在停止しているデータベースセッションの数)を簡単に、そして正確に調整させれる。
Plain SQL Support
SlickのScalaベースなクエリAPIは、Scalaコレクションを扱うかのように、データベースクエリを記述することが出来る。はじめようは、このAPIに焦点を当てたマニュアルになっている。
もし、あなたが独自のSQL文を通常のSlickのクエリと同様に非同期に実行したいと言うのならば、Plain SQL APIを利用する事が出来る。
val limit = 10.0
sql"select COF_NAME from COFFEES where PRICE < $limit".as[String]
// 変数はSQLインジェクションが無いように自動的に束縛される
// select COF_NAME from COFFEES where PRICE < ?
License
Slick is released under a BSD-Style free and open source software license. See the chapter on the commercial Slick Extensions add-on package for details on licensing the Slick drivers for the big commercial database systems.
Next Steps
- Slickを使うのが初めてならば、このままはじめようへ
- もし古いバージョンのSLickを使っていたならば、アップグレードガイドへ
- 以前にORMを利用していたならば、ORMからSlickを利用する人へへ
- もしSQLに詳しいのならば、SQLからSlickを利用する人へへ
Slick 3.0.0 documentation - 02 Supported Databases
Permalink to Suppoerted Databases — Slick 3.0.0 documentation
サポートされたデータベース
- DB2 (via slick-extensions)
- Derby/JavaDB
- H2
- HSQLDB/HyperSQL
- Microsoft Access
- Microsoft SQL Server (via slick-extensions
- MySQL
- Oracle (via slick-extensions
- PostgreSQL
- SQLite
様々なSQLデータベースへSlickなら簡単にアクセスする事が出来る。独自のSQLベースのバックエンドを持つデータベースも、プラグインを作成する事でSlickを利用することが出来る。そのようなプラグインの作成は大きな貢献となる。NoSQLのような他のバックエンドを持つようなデータベースに関しては現在開発中であるため、まだ利用する事はできない。
特別な機能については、ドライバによってサポートされているかが異なる。“Yes“は完全にサポートされているもの、その他は部分的にサポートされていたり、十分なサポートがされていないものである。個々のドライバのAPIドキュメントについては、リンク先から確認して欲しい。
訳注 表が大きいため、こちらのページを直接参照して下さい。
Slick 3.0.0 documentation - 03 Getting Started
Permalink to Getting Started — Slick 3.0.0 documentation
はじめよう
Slickを試す最も簡単方法は、Typesafe Activatorを使ってアプリケーションのテンプレートを作成することだ。以下のテンプレートはSlickのチームによって作られたものであり、Slickの新しいバージョンがリリースされる毎に更新されるだろう。
- Slickの基本を学びたいのなら、Hello Slick templateから始めると良い。これはチュートリアルやこのページにあるコードを拡張したものを含んでいる。
- Slick Plain SQL Queries templateはSlickを用いてどのようにしてクエリを実行させるかを知る事ができる。
- Slick Multi-DB Patterns templateは異なるデータベースシステムを用いたSlickのアプリケーションをどのようにして書くのか、また特別なデータベース関数に対し、Slickのクエリをどのようにして取り扱うのかを学ぶ事ができる。
- Slick TestKit Example templateはあなたが独自に作成したSlickのドライバをテストするSlick TestKitの使い方を教えてくれる。
これ以外にも、他のSlickのリリースバージョンにも対応した、コミュニティにより作られたSlickのテンプレートが数多く存在する。これらのテンプレートはTypesafeのウェブサイト上の、all Slick templatesから見つける事ができる。
Adding Slick to Your Project
Slickを既存のプロジェクトで利用するには、Maven Centralにあるライブラリを用いれば良い。sbtプロジェクトの場合、以下の記述をbuild.sbtやproject/Build.scalaに追加すれば良い。
libraryDependencies ++= Seq(
"com.typesafe.slick" %% "slick" % "|release|", "org.slf4j" %
"slf4j-nop" % "1.6.4"
)
Mavenプロジェクトの場合<dependencies>へ以下のような記述を書き加える。Scalaのバージョンプレフィックス(_2.10、_2.11)を正しく付け加える必要がある。
<dependency>
<groupId>com.typesafe.slick</groupId>
<artifactId>slick_2.10</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>1.6.4</version>
</dependency>
SlickはSLF4Jをデバッグロギングのために利用しているため、SLF4Jの実装を持ったライブラリをあなたが選んで追加する必要がある。上の例では、ロギング出力を破棄するために、slf4j-nopを追加している。もし何かしらのログ出力が欲しいのならば、Logbackのようなロギングフレームワークをslf4j-nopの代わりに追加して欲しい。
リアクティブストリームAPIは自動的に追従的な依存で取得される。
もしコネクションプールを用いたいのなら、HikariCPの依存性を追加して欲しい。
Quick Introduction
Note
このチャプターの残り部分は、Hello Slick templateを基にしている。Activatorからコードを手元に用意して、編集・実行しながらチュートリアルを読むと良い。
Slickを利用するには、あなたの利用するデータベースに対応したAPIのimport文を以下のように書き加える必要がある。
// H2データベースに接続するためのH2Driver
import slick.driver.H2Driver.api._
import scala.concurrent.ExecutionContext.Implicits.global
この例ではH2データベースを利用しているため、SlickのH2Driverをimportしている。ドライバのapiオブジェクトはdatabase handlingのようなSlickの一般的なAPIを含んでいる。
SlickのAPIは、分離されたスレッドプールに置いて、全て非同期でデータベース処理を実行する。DBIOAction構成内のあなたのコードやFutureの値を実行して取得するには、globalなExecutionContextをインポートする必要がある。SlickをPlayやAkkaを用いた大きなアプリケーションの一部として用いる場合には、そのようなフレームワークが提供しているより良いExecutionContextを利用すべきだ。
Database Configuration
データベースに接続する方法を指定するために、アプリケーションの中でDatabaseオブジェクトを作る必要がある。大抵の場合、Typesafe Configを用いて記述したapplication.confから、データベースコネクションの設定を行うだろう。application.confはPlayやAkkaでも設定を記述するために用いられている。
h2mem1 = {
url = "jdbc:h2:mem:test1"
driver = org.h2.Driver
connectionPool = disabled
keepAliveConnection = true
}
この例ではコネクションプールは用いないで、keep-alive接続をリクエストするように設定している(インメモリデータベースにコネクションプールは必要無いし、keep-aliveはデータベース利用中に接続を切らないようにするためである)。データベースオブジェクトは以下のように利用される。
val db = Database.forConfig("h2mem1")
try {
// ...
} finally db.close
Note
Databaseオブジェクトは通常スレッドプールとコネクションプールを管理する。必要がなくなった段階で、適切にシャットダウンすべきである(JVMプロセスが終了するしないに関わらず)。
Schema
Slickのクエリを記述する前に、テーブル毎にTableとTableQueryを用いてデータベーススキーマを書く必要がある。直接手で書いても良いし、スキーマコードの生成を利用して既存のデータベーススキーマから自動生成しても良い。
// SUPPLIERSテーブルの定義
class Suppliers(tag: Tag) extends Table[(Int, String, String, String, String, String)](tag, "SUPPLIERS") {
def id = column[Int]("SUP_ID", O.PrimaryKey) // 主キー
def name = column[String]("SUP_NAME")
def street = column[String]("STREET")
def city = column[String]("CITY")
def state = column[String]("STATE")
def zip = column[String]("ZIP")
// は全てのテーブルで * 射影をテーブルの型パラメータに合うように定義する
def * = (id, name, street, city, state, zip)
}
val suppliers = TableQuery[Suppliers]
...
// COFFEESテーブルの定義
class Coffees(tag: Tag) extends Table[(String, Int, Double, Int, Int)](tag, "COFFEES") {
def name = column[String]("COF_NAME", O.PrimaryKey)
def supID = column[Int]("SUP_ID")
def price = column[Double]("PRICE")
def sales = column[Int]("SALES")
def total = column[Int]("TOTAL")
def * = (name, supID, price, sales, total)
// joinなどを発行する際に用いられる外部キー
def supplier = foreignKey("SUP_FK", supID, suppliers)(_.id)
}
val coffees = TableQuery[Coffees]
全てのカラムは名前とScalaの型が必要になる。一般的に名前はSQL側では大文字とアンダースコアで、Scala側ではcamelCaseで記述される。SQLの型はScalaの型から自動的に導出される。テーブルオブジェクトにもScalaの名前とSQLの名前とその型が必要になる。テーブルの型引数は、*射影の型と合っている必要がある。このような単純な例では、全てのカラムをタプルで表現出来るが、より複雑なマッピングも可能である。
coffeesテーブルのforeignKeyの定義は、supIDの値がsuppliersテーブルのidとして存在している事を表す制約を表現するものである。ここではn:1関係を作成している。1つのCoffeesの列に対して1つのSuppliersの列が対応しているが、複数のCoffeesの列が同じSuppliersの列を指し示す事もある。この制約はデータベースレベルで強制されるものになる。
Populating the Database
インメモリのH2データベースエンジンへのコネクションは、空のデータベースを提供してくれる。クエリを実行する前に、データベーススキーマ(coffeesとsuppliersテーブルを含むもの)を作成して、テストデータを挿入してみよう。
val setup = DBIO.seq(
// 主キーや外部キーを含むテーブルを作成
(suppliers.schema ++ coffees.schema).create,
...
// supplierをいくつか挿入
suppliers += (101, "Acme, Inc.", "99 Market Street", "Groundsville", "CA", "95199"),
suppliers += ( 49, "Superior Coffee", "1 Party Place", "Mendocino", "CA", "95460"),
suppliers += (150, "The High Ground", "100 Coffee Lane", "Meadows", "CA", "93966"),
// 以下のSQLと等価
// insert into SUPPLIERS(SUP_ID, SUP_NAME, STREET, CITY, STATE, ZIP) values (?,?,?,?,?,?)
...
// coffeeをいくつか挿入(もしDBがサポートしてる場合にはバッチinsertが用いられる)
coffees ++= Seq(
("Colombian", 101, 7.99, 0, 0),
("French_Roast", 49, 8.99, 0, 0),
("Espresso", 150, 9.99, 0, 0),
("Colombian_Decaf", 101, 8.99, 0, 0),
("French_Roast_Decaf", 49, 9.99, 0, 0)
)
// 以下のSQLと等価
// insert into COFFEES(COF_NAME, SUP_ID, PRICE, SALES, TOTAL) values (?,?,?,?,?)
)
...
val setupFuture = db.run(setup)
TableQueryのddlメソッドは、テーブルを作成・削除するためDDL(data definition language)オブジェクトを生成する。複数のDDLを++により結合した場合には、たとえ循環依存が存在したとしても、正しい順番に作成と削除を実行する。
データの挿入には+=や++=が用いられる。これはScalaのミュータブルなコレクション操作APIとよく似ている。
create、+=、++=といったメソッドは、データベースへの処理の後に一定時間後に結果を生成するActionを返却する。複数のActionをシーケンスに結合し、他のActionを生成するためのコンビネータが、いくつか存在する。最もシンプルな方法は、Action.seqであり、これは返り値を破棄しながら複数のActionを順に結合するものである。例として、ActionがUnitを返却する場合などに用いる。準備されたActionはdb.runにより実行され、Future[Unit]が生成される。
Note
データベースのコネクションとトランザクションはSlickにより自動的に管理される。デフォルトでは、auto-commitモードの際にはコネクションは都度開放される。このモードでは、外部キーの影響により、
suppliersテーブルのデータをcoffeesのデータより先に挿入しなくてはならない。明示的なトランザクションブラケットで内包された処理を実行することもできる(db.run(setup.transactionally))。そのような記述を行う際には、トランザクションがコミットされる際にのみ制約が課せられるため、記述時の順序などを気にする必要はない。
Querying
テーブルからデータをイテレートさせる最もシンプルな方法を見てみよう。
// 全てのcoffeeを読み込んで、コンソールに出力する
println("Coffees:")
db.run(coffees.result).map(_.foreach {
case (name, supID, price, sales, total) =>
println(" " + name + "\t" + supID + "\t" + price + "\t" + sales + "\t" + total)
})
// 以下のSQLと等価
// select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEES
上の例はSELECT * FROM COFFEESというSQLと等価である(ただしこれは*がテーブルに定義された*射影と等しいためである)。ループの中で得られる型は、まぁ驚くこともなく、Coffeesの型引数と同じものになる。
基本的なクエリに対し、射影を追加してみよう。ここでは、Scalaのmapメソッドか、for式が用いて記述される。
// Why not let the database do the string conversion and concatenation?
val q1 = for(c <- coffees)
yield LiteralColumn(" ") ++ c.name ++ "\t" ++ c.supID.asColumnOf[String] ++
"\t" ++ c.price.asColumnOf[String] ++ "\t" ++ c.sales.asColumnOf[String] ++
"\t" ++ c.total.asColumnOf[String]
// 最初の文字列は、自動的に`LiteralColumn`へ持ち上げられる
...
// これは以下のSQLと等価になる
// select ' ' || COF_NAME || '\t' || SUP_ID || '\t' || PRICE || '\t' SALES || '\t' TOTAL from COFFEES
...
db.stream(q1.result).foreach(println)
出力は同じで、全てのカラムがタブで区切られて結合されたものになる。異なるのは、データベースエンジン内で行われた処理のみで、結果は全く変わらないまま得られる。注意して欲しいのは、ここでは文字列結合にScalaの+オペレータは使わずに、++を用いている。また、他の型から文字列への自動的な変換は存在しない。ここでは明示的にasColumnOfを用いて変換を行っている。
Reactive Streamsでも、データベースから値をストリームとして取り出し、全ての結果を得る前に順に出力させるという処理を記述出来る。
テーブルの結合と結果のフィルタリング処理は、Scalaのコレクション操作と同様の記述で行える。
// 9.0未満のpriceとなるcoffeeから、coffeeの名前とsupplierの名前を、joinを用いて取得する
val q2 = for {
c <- coffees if c.price < 9.0
s <- suppliers if s.id === c.supID
} yield (c.name, s.name)
// 以下のSQLと等価
// select c.COF_NAME, s.SUP_NAME from COFFEES c, SUPPLIERS s where c.PRICE < 9.0 and s.SUP_ID = c.SUP_ID
Warning
2つの値の比較には、
==の代わりに===を、!=の代わりに=!=を用いて欲しい。なぜならこれは既にAnyを基に実装されたオペレータであり、拡張することが出来ないためである。<、<=、>=、>のような比較オペレータはそのままのものを用いる事が出来る。
suppliers if s.id === c.supIDという表現は、Coffees.supplierという外部キーを用いて書き換える事ができる。joinの条件を繰り返し書く代わりに、外部キーを直接記述すれば良いのである。
val q3 = for {
c <- coffees if c.price < 9.0
s <- c.supplier
} yield (c.name, s.name)
// 以下のSQLと等価
// select c.COF_NAME, s.SUP_NAME from COFFEES c, SUPPLIERS s where c.PRICE < 9.0 and s.SUP_ID = c.SUP_ID
Slick 3.0.0 documentation - 04 Database Configuration
Permalink to Database Configuration — Slick 3.0.0 documentation
データベース設定
どのようにしてデータベースへ接続するかを、Databaseオブジェクトを通してSlickに教えてあげなくてはならない。slick.jdbc.JdbcBackend.Database オブジェクトを作成するためのfactory methodsがいくつかある。
Using Typesafe Config
PlayやAkkaで使われてるapplication.confに、Typesafe Configでデータベースに接続する設定を記述する方法を我々は推奨している。
mydb = {
dataSourceClass = "org.postgresql.ds.PGSimpleDataSource"
properties = {
databaseName = "mydb"
user = "myuser"
password = "secret"
}
numThreads = 10
}
Database.forConfig を用いて、設定を読み込むことができる。引数などの詳細についてはAPI documentationを見て欲しい。
val db = Database.forConfig("mydb")
Using a JDBC URL
JDBC URLはforURLに渡してあげる(URLについては各種利用するデータベースのJDBCドライバのドキュメントを読んで欲しい)。
val db = Database.forURL("jdbc:h2:mem:test1;DB_CLOSE_DELAY=-1", driver="org.h2.Driver")
ここでは、JVMが終了するまで使うことの出来るtest1という名前の、空のインメモリH2データベースへの情報を記述し、接続を作成している(DB_CLOSE_DELAY=-1ってのはH2データベース特有の設定だ)。
Using a DataSource
DataSourceはforDataSourceに渡してあげる。これは、アプリケーションフレームワークのコネクションプールから得られたものを、Slickのプールへと繋げている。
val db = Database.forDataSource(dataSource: javax.sql.DataSource)
Using a JNDI Name
もしJNDIを使っているのならば、DataSourceオブジェクトを見つけられるように、JNDIの名前をforNameへ渡してあげたら良い。
val db = Database.forName(jndiName: String)
Database thread pool
どのDatabaseもスレッドプールを管理するAsyncExecutorを保持している。このスレッドプールはデータベースのI/O Actionを非同期に実行するためのものである。そのサイズは、Databaseオブジェクトが最も良いパフォーマンスを出せるよう調整すべき重要なパラメータとなる。この値には、非同期アプリケーションで利用していた コネクションプール数 を設定すべきである(HikariCPのAbout Pool Sizingなどのドキュメントも参考にして欲しい)。Database.forConfigを用いると、スレッドプールは、直接外部の設定からコネクションパラメータなどと一緒に設定する事が出来る。もしDatabaseを取得するのに、その他のファクトリーメソッドを用いているのなら、デフォルトの設定をそのまま用いるか、AsyncExecutorをカスタマイズして利用して欲しい。
val db = Database.forURL("jdbc:h2:mem:test1;DB_CLOSE_DELAY=-1", driver="org.h2.Driver",
executor = AsyncExecutor("test1", numThreads=10, queueSize=1000))
Connection pools
コネクションプールを用いているのなら(プロダクション環境などでは利用していると思うが…)、コネクションプール数の最小値は少なくとも先のと同じ数を設定すべきである。コネクションプール数の最大値については、同期的なアプリケーションにおいて利用される数より多めの値を設定するのが良い。スレッドプール数を超えるコネクションは、データベースセッションをオープンし続けるために、他のコネクションが要求された際に用いられたりする(e.g. トランザクション中の非同期的な計算結果を待っている時など)。
ちなみに、Database.forConfigを利用した際には、スレッドプール数を基に計算されたコネクションプール数がデフォルト値として提供されることになる。
Slickはプリペアドステートメントを利用可能な場所では利用しているものの、Slick側でそれらをキャッシュしたりはしていない。それゆえ、あなた自身でコネクションプールの設定時に、プリペアドステートメントのキャッシュを有効化して欲しい。
DatabaseConfig
Databaseの設定のトップにおいて、DatabaseConfigのフォーム内にSlickドライバに合うDatabaseを追加する設定も置くことが出来る。これを利用すると、異なるデータベースを利用する際に、簡単に設定ファイルを変更出来るようにするための抽象化が簡単に出来る。
driverにSlickのドライバを、dbにデータベースの設定を記述したDatabaseConfigの例は次のようになる。
tsql {
driver = "slick.driver.H2Driver$"
db {
connectionPool = disabled
driver = "org.h2.Driver"
url = "jdbc:h2:mem:tsql1;INIT=runscript from 'src/main/resources/create-schema.sql'"
}
}
Slick 3.0.0 documentation - 05 Database I/O Actions
Permalink to Database I/O Actions — Slick 3.0.0 documentation
データベースI/Oアクション
クエリの結果を取得したり(myQuery.result)、テーブルを作成したり(myTable.schema.create)、データを挿入する(myTable += item)といったデータベースに対して実行する全ての事柄は、DBIOActionのインスタンスになる。
Database I/O Actions はいくつかの異なるコンビネータにより結合されるが(詳細はDBIOAction classとDBIO objectで)、それらはいつも直列に実行され、(少なくとも概念上は)1つのデータベースセッションにおいて実行される。
大抵の場合、DBIOの型エイリアスを通常時のデータベースI/Oアクションとして、StreamingDBIOの型エイリアスををストリーミング可能なデータベースI/Oアクションとして利用したいと思うだろう。これらは、DBIOActionによってサポートされた副次的な effect types を省略させる(They omit the optional *effect types* supported by slick.dbio.DBIOAction.)。
Executing Database I/O Actions
DBIOActionsを実行すると、データベースから得られた具象化された結果やストリーミングデータを得る事が出来る。
Materialized
データベースに対しDBIOActionを実行し、具象化された結果を得るにはrunを用いる。これは例えば、単一のクエリ結果を引く場合(myTable.length.result)、コレクションを結果として得るクエリを引く場合(myTable.to[Set].result)などに利用される。どのDBIOActionもこのような実行処理をサポートしている。
runが呼ばれた時点で、アクションの実行が開始される。そして具象化された結果は非同期に処理が実行され終了するものとして、Futureにくるまって返却される。
val q = for (c <- coffees) yield c.name
val a = q.result
val f: Future[Seq[String]] = db.run(a)
f.onSuccess { case s => println(s"Result: $s") }
Streaming
コレクションが得られるクエリには、ストリーミングの結果を返却する機能が備わっている。この場合、実際のコレクションの型は無視され、要素が直接Reactive StreamsのPublisherを通して返却されることになる。これはAkka Streamsにより処理・計算されたものとなる。
DBIOActionの実行処理は、Subscriberをストリームに繋げるまで実行されない。Subscriberは1つだけ 購読 させる事が可能であり、それ以上の 購読 を行おうとするとそれらは失敗してしまう。DBIOActionのストリーミング部分において、ストリームの各要素は利用出来る状態になるとすぐに実行可能であると合図を送る。例えばトランザクションの中でストリーミング処理を行った場合にも、全ての要素は正常に届けられ、トランザクションがコミットされなかった場合にもきちんとストリームも失敗するようにできている。
val q = for (c <- coffees) yield c.name
val a = q.result
val p: DatabasePublisher[String] = db.stream(a)
...
// .foreach is a convenience method on DatabasePublisher.
// Use Akka Streams for more elaborate stream processing.
p.foreach { s => println(s"Element: $s") }
JDBCの結果集合をストリーミングする際、もしSubscriberが多くのデータを受け取る準備が出来ていないのなら、次の結果ページはバックグラウンドにバッファリングされる。一方で、全ての結果要素は同期的に渡されるし、結果集合は同期処理が終了する前に先に進んでしまったりはしない。これにより、結果集合の状態に依存するBlobのようなJDBCの低レベルな値に対しても同期的なコールバックが利用可能となる。mapResultのような便利なメソッドがこの目的のために提供されている。
val q = for (c <- coffees) yield c.image
val a = q.result
val p1: DatabasePublisher[Blob] = db.stream(a)
val p2: DatabasePublisher[Array[Byte]] = p1.mapResult { b =>
b.getBytes(0, b.length().toInt)
}
Transactions and Pinned Sessions
いくつかの小さいアクションで構成されたDBIOActionを実行する際には、Slickはコネクションプールから得られたセッションを要求し、その後セッションを開放する。データベース外の計算から結果を得るのを待ち合わせる間(例えば、flatMap)、不必要なセッションは保持されない。データベースに計算させることなく、2つのデータベースのアクションを結合するDBIOAction combinators(andThenやzip)は、1つのセッション内で融合されたアクションを実行する副作用を伴いつつ、より効率的にこれらのアクションを融合する。1つのセッションでの利用を強制するには、withPinnedSessionを利用すれば良い。これを用いる事で、データベース外での計算を待ち合わせる際に、既存のセッションを開き続けたままにしておくことが出来る。
トランザクションの利用を強制するtransactionallyと呼ばれるコンビネータもある。これは、実行されるDBIOActionの処理全体が自動的に成功か失敗のいずれかに収まる。
Warning
失敗というのは
transactionallyでラップされた個々のDBIOActionのアトミック性を保証するものでは無いため、この時点でエラー回復を図るコンビネータを適用すべきではない。作成されたデータベース側のトランザクションは、transactionallyアクションの外側でコミットやロールバックを行う。
val a = (for {
ns <- coffees.filter(_.name.startsWith("ESPRESSO")).map(_.name).result
_ <- DBIO.seq(ns.map(n => coffees.filter(_.name === n).delete): _*)
} yield ()).transactionally
val f: Future[Unit] = db.run(a)
JDBC Interoperability
Slickで利用出来ない機能を使うためにJDBCのレベルを落とすには、SimpleDBIOアクションを用いれば良い。SimpleDBIOアクションは、データベースのスレッド上で実行され、JDBCのConnectionへの接続を得るものである。
val getAutoCommit = SimpleDBIO[Boolean](_.connection.getAutoCommit)
Slick 3.0.0 documentation - 06 Schemas
Permalink to Schemas — Slick 3.0.0 documentation
スキーマ
この章では、既存のデータベースを持たない新しいアプリケーションを作る際、どのようにしてScalaのコードでデータベーススキーマを記述するのかを説明する。もしデータベーススキーマを既に持っているのなら、code generatorを利用することで、手で書く手間は省ける。
Table Rows
型安全なクエリをScalaのAPIを通して利用するには、データベーススキーマに応じたTableクラスを定義する必要がある。これは、テーブルの構造を表現するものである。
class Coffees(tag: Tag) extends Table[(String, Int, Double, Int, Int)](tag, "COFFEES") {
def name = column[String]("COF_NAME", O.PrimaryKey)
def supID = column[Int]("SUP_ID")
def price = column[Double]("PRICE")
def sales = column[Int]("SALES", O.Default(0))
def total = column[Int]("TOTAL", O.Default(0))
def * = (name, supID, price, sales, total)
}
全てのカラムは、columnメソッドを通して定義される。どのカラムもScalaの型と、データベースで利用されるカラム名を持つ(カラム名は一般的には大文字)。以下のプリミティブな型は、JdbcProfileにおいてJDBCベースなデータベースのためのサポートがなされている(個々のデータベースドライバによっていくつかの制限が存在するが)。
- 数値型: Byte, Short, Int, Long, BigDecimal, Float, Double
- LOB型: java.sql.Blob, java.sql.Clob, Array[Byte]
- Date型: java.sql.Date, java.sql.Time, java.sql.Timestamp
- Boolean
- String
- Unit
- java.util.UUID
Nullになりえるカラムについては、Tがプリミティブ型でサポートされている場合、Option[T]で表現することが出来る。
Note
このOptionに対する全ての操作は、ScalaのOption操作と異なり、データベースのnullプロパゲーションセマンティクスを用いることになる点に注意して欲しい。特に、
None === Noneという式はNoneになる。これはSlickのメジャーリリースで将来的に変更されるかもしれない。
カラム名の後ろには、columnの定義につけるオプションを付与する事ができる。適用可能なオプションは、テーブルのOオブジェクトを通して利用出来る。以下のオプションが、JdbcProfile用に定義されている。
PrimaryKey- DDLステートメントを作成する際に、このカラムが主キーであることをマークする
Default[T](defaultValue: T)- カラムの値を設定せずにテーブルにデータを挿入する際のデフォルト値を設定する。この情報は、DDLステートメントを作成する時のみに利用される。
DBType(dbType: String)- DDBステートメントのために、データベースの型を明示する際に利用する。例として、
String型のカラムに対して、DBType("VARCHAR(20)")を明示して指定したりする。
- DDBステートメントのために、データベースの型を明示する際に利用する。例として、
AutoInc- DDBステートメントを作成する際に、このカラムがauto incrementさせるカラムであることを指定する。他のカラムオプションと異なりこれはDDL作成時以外にも利用される。多くのデータベースがAutoIncなカラム以外から値を返すのを許容していないため、Slickは値を返すカラムが適切にAutoIncなカラムになっているかをチェックしている。
NotNull,Nullable- テーブルのDDLステートメントを作成する際に、nullを許容するか・しないかを明示して指定する。
Optionかそうでないかでnullを許容するかを指定出来るため、一般的にはこのオプションは用いられない。
- テーブルのDDLステートメントを作成する際に、nullを許容するか・しないかを明示して指定する。
全てのテーブルはデフォルトの射影として*メソッドを定義している。これは、クエリの結果として列を返す際に、あなたがどんな情報を求めているのかを説明するためのものである。Slickの*射影は、データベース内のカラムと一致している必要は無い。何かしらの計算結果を追加したり、いくつかのカラムを省いて使っても良い。*射影の結果は、Tableの型引数と一致する必要があり、これはマッピングされた何かしらのクラスか、カラムが用いられることになるだろう。
もしデータベースが schema names を必要とするなら、テーブル名の前にその名前を明示して欲しい。
class Coffees(tag: Tag)
extends Table[(String, Int, Double, Int, Int)](tag, Some("MYSCHEMA"), "COFFEES") {
//...
}
Table Query
Tableクラスに対して、実際のデータベーステーブルを表すTableQueryも必要になるだろう。
val coffees = TableQuery[Coffees]
TableQuery[T]というシンプルなシンタックスはマクロであり、これはnew TableQuery(new T(_))のようなテーブルのコンストラクタを呼び出すTableQueryのインスタンスとなる。
テーブルに関連する追加機能を提供するために、TableQueryを継承しても良いだろう。
object coffees extends TableQuery(new Coffees(_)) {
val findByName = this.findBy(_.name)
}
Mapped Tables
*射影の結果を独自の型にマッピングしたいのなら、<>オペレータを利用して双方向マッピングを定義してあげると良い。
case class User(id: Option[Int], first: String, last: String)
class Users(tag: Tag) extends Table[User](tag, "users") {
def id = column[Int]("id", O.PrimaryKey, O.AutoInc)
def first = column[String]("first")
def last = column[String]("last")
def * = (id.?, first, last) <> (User.tupled, User.unapply)
}
val users = TableQuery[Users]
これはapplyとunapplyを持つケースクラス用に最適化されているが、任意のマッピングを行う事も可能である。適切に型を推測してくれるタプルを生成してくれる.shapedという便利なメソッドもある。任意のマッピングを行う場合には、マッピング用の型アノテーションを適宜書いて欲しい。
ケースクラスのコンパニオンオブジェクトを手で書いている場合には、Scalaの機能に合うように実装が行われている場合にのみ、.tupledは上手く動作する。他にも(User.apply _).tupledなどを使ったりも出来るだろう。 SI-3664やSI-4808も目を通しておいて欲しい。
Constraints
外部キーは、TableのforeignKeyによって定義される。第一引数には、制約名、関連カラム、関連テーブルの3つを渡す。続く第二引数は、関連テーブルの紐付けるカラムに加えて、OnUpdateやOnDeleteのようなForeignKeyActionに関するものを指定できる。ForeignKeyActionのデフォルト値はNoActionとなっている。テーブルのDDLステートメントが作成された時に、宣言された外部キーが定義される。
class Suppliers(tag: Tag) extends Table[(Int, String, String, String, String, String)](tag, "SUPPLIERS") {
def id = column[Int]("SUP_ID", O.PrimaryKey)
//...
}
val suppliers = TableQuery[Suppliers]
class Coffees(tag: Tag) extends Table[(String, Int, Double, Int, Int)](tag, "COFFEES") {
def supID = column[Int]("SUP_ID")
//...
def supplier = foreignKey("SUP_FK", supID, suppliers)(_.id, onUpdate=ForeignKeyAction.Restrict, onDelete=ForeignKeyAction.Cascade)
// compiles to SQL:
// alter table "COFFEES" add constraint "SUP_FK" foreign key("SUP_ID")
// references "SUPPLIERS"("SUP_ID")
// on update RESTRICT on delete CASCADE
}
val coffees = TableQuery[Coffees]
データベースに定義された制約とは別に、join時に利用出来る外部キーを用意する事もできる。この外部キーは、他のテーブルから関連を取得する便利メソッドとして利用することが出来る。
def supplier = foreignKey("SUP_FK", supID, suppliers)(_.id, onUpdate=ForeignKeyAction.Restrict, onDelete=ForeignKeyAction.Cascade)
def supplier2 = suppliers.filter(_.id === supID)
主キー制約はprimaryKeyというメソッドを用いる事で同様に定義出来る。これはO.PrimaryKeyを使う時とは異なり、複合主キーを定義する際に役立つ。
class A(tag: Tag) extends Table[(Int, Int)](tag, "a") {
def k1 = column[Int]("k1")
def k2 = column[Int]("k2")
def * = (k1, k2)
def pk = primaryKey("pk_a", (k1, k2))
// compiles to SQL:
// alter table "a" add constraint "pk_a" primary key("k1","k2")
}
インデックスについても、indexメソッドを用いる事で同様に定義出来る。これらはデフォルトではユニーク制約はつかず、もし必要な場合にはuniqueパラメータに値をセットして欲しい。
class A(tag: Tag) extends Table[(Int, Int)](tag, "a") {
def k1 = column[Int]("k1")
def k2 = column[Int]("k2")
def * = (k1, k2)
def idx = index("idx_a", (k1, k2), unique = true)
// compiles to SQL:
// create unique index "idx_a" on "a" ("k1","k2")
}
全ての制約は、テーブルに定義された適切な返り値と共に、メソッドが都度探索される。この挙動はtableConstraintsメソッドをオーバーライドする事でカスタマイズ可能だ。
Data Definition Language
テーブルのDDLステートメントはそのテーブルのTableQueryのschemaメソッドを基に作成される。複数のDDLオブジェクトは++メソッドにより1つのDDLオブジェクトに結合出来る。これはcreate時もdrop時も全ての制約に対し、たとえ循環依存がテーブル間に存在したとしても、正しい挙動をするように実行されるものとなる。createやdropメソッドはDDLステートメントを実行するActionを生成する。
val schema = coffees.schema ++ suppliers.schema
db.run(DBIO.seq(
schema.create,
//...
schema.drop
))
statemensメソッドを用いる事で、SQLのコードを取得出来る。スキーマのActionは、1つ以上のステートメントを生成するようになっている。
schema.create.statements.foreach(println)
schema.drop.statements.foreach(println)
Slick 3.0.0 documentation - 07 Queries
Permalink to Queries — Slick 3.0.0 documentation
クエリ
本章ではselect, insert, update, deleteといった処理を、SlickのクエリAPIで、どのようにして型安全なクエリを記述するのかを説明する。
このAPIは Lifted Embedding と呼ばれる。これは、実際にはScalaの基本的な型を操作するのではなく、Repの型コンストラクタへと 持ち上げられた型 を用いてる事に由来する。以下のように、Scalaのコレクション操作で扱う型と比較すると分かりやすい。
case class Coffee(name: String, price: Double)
val coffees: List[Coffee] = //...
...
val l = coffees.filter(_.price > 8.0).map(_.name)
// ^ ^ ^
// Double Double String
Slickにおいて似たような記述を行うと、以下のようになる。
class Coffees(tag: Tag) extends Table[(String, Double)](tag, "COFFEES") {
def name = column[String]("COF_NAME")
def price = column[Double]("PRICE")
def * = (name, price)
}
val coffees = TableQuery[Coffees]
...
val q = coffees.filter(_.price > 8.0).map(_.name)
// ^ ^ ^
// Rep[Double] Rep[Double] Rep[String]
全ての基本的な型はRepへと持ち上げられる。Coffeesの列を表す型もRep[(String, Double)]として扱われるのと等価になる。8.0というリテラルも、暗黙的変換により、Rep[Double]となる。これは>オペレータがRep[Double]を要求するためである。この持ち上げ操作は、クエリを生成する際のシンタックスツリーを作成するのに必要になる。Scalaの基本的な関数や値はSQLへ変換するのに十分な情報を含んではいない。
Expressions
レコードでもコレクションでも無い単純なスカラー値は、暗黙的なTypedType[T]が存在し、Rep[T]により表現される。
クエリ内で一般的に用いられるオペレータやメソッドは、ExtensionMethodConversionsで定義された暗黙的な変換を通して利用される。実際のメソッドはAnyExtensionMethods、ColumnExtensionMethods、NumericColumnExtensionMethods、BooleanColumnExtensionMethods、StringColumnExtensionMethodsに存在する。(cf. ExtensionMethods)
Warning
Scalaの基本的な比較演算子は、凡そ同じように動作するものの、
==と!=に関しては、===と=!=を代わりに用いなくてはならない。これはこれらのメソッドがAnyに定義されていることから拡張する事が出来ないためである。
コレクションはQueryクラスによりRep[Seq[T]]のように表現される。ここにはflatMap、filter、take、groupByのような基本的なコレクションメソッドが含まれている。2つの異なる複合型を表すために(持ち上げられたものと、持ち上げられる前のもの e.g. Query[(Rep[Int], Rep[String]), (Int, String), Seq])、これらのシグネチャはとても複雑なものになっている。ただ意味的には基本的にScalaのコレクションと同じようなものになっていることは確認して欲しい。
SingleColumnQueryExtensionMethodsへの暗黙的変換により、クエリやスカラー値のためのメソッドが数多く用意されている。
Sorting and Filtering
並び替えやフィルタリングを行うための様々なメソッドが存在する。これらは、Queryから新しいQueryを生成して返す。
val q1 = coffees.filter(_.supID === 101)
// compiles to SQL (simplified):
// select "COF_NAME", "SUP_ID", "PRICE", "SALES", "TOTAL"
// from "COFFEES"
// where "SUP_ID" = 101
...
val q2 = coffees.drop(10).take(5)
// compiles to SQL (simplified):
// select "COF_NAME", "SUP_ID", "PRICE", "SALES", "TOTAL"
// from "COFFEES"
// limit 5 offset 10
...
val q3 = coffees.sortBy(_.name.desc.nullsFirst)
// compiles to SQL (simplified):
// select "COF_NAME", "SUP_ID", "PRICE", "SALES", "TOTAL"
// from "COFFEES"
// order by "COF_NAME" desc nulls first
...
// building criteria using a "dynamic filter" e.g. from a webform.
val criteriaColombian = Option("Colombian")
val criteriaEspresso = Option("Espresso")
val criteriaRoast:Option[String] = None
...
val q4 = coffees.filter { coffee =>
List(
criteriaColombian.map(coffee.name === _),
criteriaEspresso.map(coffee.name === _),
criteriaRoast.map(coffee.name === _) // not a condition as `criteriaRoast` evaluates to `None`
).collect({case Some(criteria) => criteria}).reduceLeftOption(_ || _).getOrElse(true: Column[Boolean])
}
// compiles to SQL (simplified):
// select "COF_NAME", "SUP_ID", "PRICE", "SALES", "TOTAL"
// from "COFFEES"
// where ("COF_NAME" = 'Colombian' or "COF_NAME" = 'Espresso')
Joining and Zipping
joinは2つの異なるテーブルやクエリに対して、1つのクエリを適用するのに用いられる。ApplicativeとMonadicの2種類のjoinの書き方が存在する。
Applicative joins
Applicativeなjoinはそれぞれの結果を取得するクエリに対し、2つのクエリを結合するメソッドを呼ぶ事で実行出来る。SQLにおけるjoinと同様の制約がかかり、右側の式は左側の式に依存しなかったりする。これはScalaのスコープにおけるルールを通して自然に強制される。
val crossJoin = for {
(c, s) <- coffees join suppliers
} yield (c.name, s.name)
// compiles to SQL (simplified):
// select x2."COF_NAME", x3."SUP_NAME" from "COFFEES" x2
// inner join "SUPPLIERS" x3
...
val innerJoin = for {
(c, s) <- coffees join suppliers on (_.supID === _.id)
} yield (c.name, s.name)
// compiles to SQL (simplified):
// select x2."COF_NAME", x3."SUP_NAME" from "COFFEES" x2
// inner join "SUPPLIERS" x3
// on x2."SUP_ID" = x3."SUP_ID"
...
val leftOuterJoin = for {
(c, s) <- coffees joinLeft suppliers on (_.supID === _.id)
} yield (c.name, s.map(_.name))
// compiles to SQL (simplified):
// select x2."COF_NAME", x3."SUP_NAME" from "COFFEES" x2
// left outer join "SUPPLIERS" x3
// on x2."SUP_ID" = x3."SUP_ID"
...
val rightOuterJoin = for {
(c, s) <- coffees joinRight suppliers on (_.supID === _.id)
} yield (c.map(_.name), s.name)
// compiles to SQL (simplified):
// select x2."COF_NAME", x3."SUP_NAME" from "COFFEES" x2
// right outer join "SUPPLIERS" x3
// on x2."SUP_ID" = x3."SUP_ID"
...
val fullOuterJoin = for {
(c, s) <- coffees joinFull suppliers on (_.supID === _.id)
} yield (c.map(_.name), s.map(_.name))
// compiles to SQL (simplified):
// select x2."COF_NAME", x3."SUP_NAME" from "COFFEES" x2
// full outer join "SUPPLIERS" x3
// on x2."SUP_ID" = x3."SUP_ID"
outer joinの節では、yieldの中でmapしている。これらのjoinにおいては追加でNULLになるようなカラムが生じ、結果のカラム型がOptionに包まって返却されるためである(Noneになるのは、対応する列がなかった時など)。
Monadic joins
MonadicなjoinはflatMapを利用する事で自動的に生成される。右辺が左辺に依存するため、理論上MonadicなjoinはApplicativeなjoinより強力なものとなる。一方で、これは通常のSQLに適したものとはならない。そのため、SlickはMonadicなjoinをApplicativeなjoinへと変換している。もしMonadicなjoinを適切な形に変換出来なければ、実行時に失敗する事になるだろう。
cross-joinはQueryのflatMapにより作成される。1つ以上のジェネレータを用いる際には、for式が役立つ。
val monadicCrossJoin = for {
c <- coffees
s <- suppliers
} yield (c.name, s.name)
// compiles to SQL:
// select x2."COF_NAME", x3."SUP_NAME"
// from "COFFEES" x2, "SUPPLIERS" x3
もし何かしらのフィルタリングを行うのなら、それはinner joinとなる。
val monadicInnerJoin = for {
c <- coffees
s <- suppliers if c.supID === s.id
} yield (c.name, s.name)
// compiles to SQL:
// select x2."COF_NAME", x3."SUP_NAME"
// from "COFFEES" x2, "SUPPLIERS" x3
// where x2."SUP_ID" = x3."SUP_ID"
このMonadicなjoinはScalaコレクションのflatMapを利用した時と同じ意味を持つ。
Note
SlickはMonadicなjoinに対し暗黙的なjoin(
select ... from a, b where ...)を、Applicativeなjoinに対し明示的なjoin(select ... from a join b on ...)を生成する。これについては、将来のバージョンで変更があるかもしれない。
Zip joins
関係でデータベースによってサポートされている一般的なApplicative joinに加えて、Slickは2つのクエリのペアを作成するzip joinを提供している。これはzipやzipWithメソッドを用いれば利用でき、Scalaコレクションで利用するものと同じような挙動をするものである。
val zipJoinQuery = for {
(c, s) <- coffees zip suppliers
} yield (c.name, s.name)
...
val zipWithJoin = for {
res <- coffees.zipWith(suppliers, (c: Coffees, s: Suppliers) => (c.name, s.name))
} yield res
また別のzip joinとして、zipWithIndexというものも存在する。これは0から始まる無限数列をクエリ結果と結合してくれるものである。この数列はSQLデータベースによって提供されたものではなく、Slickがサポートしているものでもない。ただの数字を吐く関数とSQLの結果を統合したものとして、zipWithIndexがプリミティブなオペレータとして提供されているのである。
val zipWithIndexJoin = for {
(c, idx) <- coffees.zipWithIndex
} yield (c.name, idx)
Unions
互換のある2つのクエリは++(もしくはunionAll)やunionで結合することが出来る。
val q1 = coffees.filter(_.price < 8.0)
val q2 = coffees.filter(_.price > 9.0)
...
val unionQuery = q1 union q2
// compiles to SQL (simplified):
// select x8."COF_NAME", x8."SUP_ID", x8."PRICE", x8."SALES", x8."TOTAL"
// from "COFFEES" x8
// where x8."PRICE" < 8.0
// union select x9."COF_NAME", x9."SUP_ID", x9."PRICE", x9."SALES", x9."TOTAL"
// from "COFFEES" x9
// where x9."PRICE" > 9.0
...
val unionAllQuery = q1 ++ q2
// compiles to SQL (simplified):
// select x8."COF_NAME", x8."SUP_ID", x8."PRICE", x8."SALES", x8."TOTAL"
// from "COFFEES" x8
// where x8."PRICE" < 8.0
// union all select x9."COF_NAME", x9."SUP_ID", x9."PRICE", x9."SALES", x9."TOTAL"
// from "COFFEES" x9
// where x9."PRICE" > 9.0
unionは重複する値については省いてしまうのに対し、++は個々のクエリ結果を単純に、より効率的に繋げるものとなっている。
Aggregation
集約関数はQueryから単一の値、主に計算された数値を返すものである。
val q = coffees.map(_.price)
...
val q1 = q.min
// compiles to SQL (simplified):
...
val q2 = q.max
// compiles to SQL (simplified):
// select max(x4."PRICE") from "COFFEES" x4
...
val q3 = q.sum
// compiles to SQL (simplified):
// select sum(x4."PRICE") from "COFFEES" x4
...
val q4 = q.avg
// compiles to SQL (simplified):
// select avg(x4."PRICE") from "COFFEES" x4
集約クエリはコレクションではなく、スカラー値を返却する。いくつかの集約関数は以下のような恣意的なクエリで定義されている。
val q1 = coffees.length
// compiles to SQL (simplified):
// select count(1) from "COFFEES"
...
val q2 = coffees.exists
// compiles to SQL (simplified):
// select exists(select * from "COFFEES")
グループ化はgroupByメソッドにより処理出来る。これはScalaのコレクションでの操作と同じような意味を持つ。
val q = (for {
c <- coffees
s <- c.supplier
} yield (c, s)).groupBy(_._1.supID)
val q2 = q.map { case (supID, css) =>
(supID, css.length, css.map(_._1.price).avg)
}
// compiles to SQL:
// select x2."SUP_ID", count(1), avg(x2."PRICE")
// from "COFFEES" x2, "SUPPLIERS" x3
// where x3."SUP_ID" = x2."SUP_ID"
// group by x2."SUP_ID"
中間クエリであるqはネストされたQueryの値を持っている。クエリを実行した際に、ネストしたコレクションが返却される。それゆえq2においては、集約関数を用いてネストを解消している。
Querying
クエリによる選択はresultメソッドを呼ぶことでActionへ変換される。Actionはストリームか個々に分割された方法、もしくは他のアクションを混在したものとして直接実行される。
val q = coffees.map(_.price)
val action = q.result
val result: Future[Seq[Double]] = db.run(action)
val sql = action.statements.head
もし結果を1つだけ受け取りたいのなら、headかheadOptionを用いれば良い。
Deleting
削除はクエリの場合と同じように動作する。はじめに削除したい行をクエリで選択した上で、deleteメソッドを呼ぶことで削除を行うActionが得られる。
val q = coffees.filter(_.supID === 15)
val action = q.delete
val affectedRowsCount: Future[Int] = db.run(action)
val sql = action.statements.head
削除を行うクエリは、1つのテーブルのみを指定しなくてはならない。どんな射影も無視され、行はまるまる削除される。
Inserting
挿入は1つのテーブルから特定のカラムを射影したものに対して実行する。テーブルを直接用いた場合には、挿入は*射影に対して実行される。挿入時にいくつかのカラムを省略した場合には、テーブル定義にあるデフォルト値が用いられるか、明示的なデフォルト値が無い場合には型に応じたデフォルト値が挿入される。挿入Actionに関する全てのメソッドは、CountingInsertActionComposerかReturningInsertActionComposerに定義されている。
val insertActions = DBIO.seq(
coffees += ("Colombian", 101, 7.99, 0, 0),
coffees ++= Seq(
("French_Roast", 49, 8.99, 0, 0),
("Espresso", 150, 9.99, 0, 0)
),
// "sales" と "total" にはデフォルト値として0が入る
coffees.map(c => (c.name, c.supID, c.price)) += ("Colombian_Decaf", 101, 8.99)
)
// insertを行うsqlのステートメントを取得
val sql = coffees.insertStatement
// compiles to SQL:
// INSERT INTO "COFFEES" ("COF_NAME","SUP_ID","PRICE","SALES","TOTAL") VALUES (?,?,?,?,?)
AutoIncがついたカラムが挿入された際には、そのカラムに対する挿入値は無視され、データベースが生成した適切な値が挿入される。大抵の場合、自動で生成された主キーの値などを返り値として取得したいと考えるだろう。デフォルトでは+=は影響を与えた行の数を返却する(普通は成功時に1が返る)。++=はOptionに包まれた結果数を返す。Noneになるのはデータベースシステムが影響を与えた数を返さない時である。これらの返り値はreturningメソッドを用いることで、好きな値が返るように変更出来る。この場合、+=に対して単一の値やタプルを返すように設定すると、++=にはその値のSeqが返却されることになる。以下の様な記述で、AutoIncで生成された主キーを返すことが出来る。
val userId =
(users returning users.map(_.id)) += User(None, "Stefan", "Zeiger")
Note
多くのデータベースでは、1つのテーブルのAutoIncrementな主キーのみを返却することを許可している。もし他のカラムについても同様の事をしようとしたならば、データベースがサポートしていない時には
SlickExceptionが投げられる。
returningにintoを続けて用いると、挿入された値と自動生成された値をもとに返り値を変更する事ができる。得られたidを用いて更新されたオブジェクトを返却する例は以下の通りとなる。
val userWithId =
(users returning users.map(_.id)
into ((user,id) => user.copy(id=Some(id)))
) += User(None, "Stefan", "Zeiger")
クライアント側でデータを挿入する以外にも、データベースサーバ側で実行されるスカラー表現やQueryを作る事でデータを挿入することも出来る。
class Users2(tag: Tag) extends Table[(Int, String)](tag, "users2") {
def id = column[Int]("id", O.PrimaryKey)
def name = column[String]("name")
def * = (id, name)
}
val users2 = TableQuery[Users2]
val actions = DBIO.seq(
users2.schema.create,
users2 forceInsertQuery (users.map { u => (u.id, u.first ++ " " ++ u.last) }),
users2 forceInsertExpr (users.length + 1, "admin")
)
この場合、AutoIncなカラムは 無視されない 。
Updating
更新は更新を行いたいデータを選択してから、新しいデータで置き換える事で実行される。更新時の返り値は計算された値ではなく、1つのテーブルから取得された生のカラムをそのまま返却しなくてはならない。更新に関連するメソッドは、UpdateExtensionMethodsで定義されている。
val q = for { c <- coffees if c.name === "Espresso" } yield c.price
val updateAction = q.update(10.49)
// 値を更新することなくステートメントを取得する
val sql = q.updateStatement
// compiles to SQL:
// update "COFFEES" set "PRICE" = ? where "COFFEES"."COF_NAME" = 'Espresso'
現時点では、データベースに用意された更新用の変換関数等を利用したりすることは出来ない。
Compiled Queries
通常、データベースクエリはいくつかのパラメータに依存している(IDは一致する列を取得するために用いられるなど)。パラメータ化されたQueryオブジェクトを実行の度に作ることも出来るが、これはSlickが毎度クエリをコンパイルするコストが高くついてしまう(パラメータに値を代入しない場合など特に)。パラメータ化されたクエリ関数を事前にSlick側でコンパイルする、より効率的な方法が存在する。
def userNameByIDRange(min: Rep[Int], max: Rep[Int]) =
for {
u <- users if u.id >= min && u.id < max
} yield u.first
val userNameByIDRangeCompiled = Compiled(userNameByIDRange _)
// このクエリは1度しかコンパイルされない
val namesAction1 = userNameByIDRangeCompiled(2, 5).result
val namesAction2 = userNameByIDRangeCompiled(1, 3).result
// .insert にも .update にも .delete にも使える
これは個々のカラムやカラムのrecordsをパラメータに取る全てのメソッドに対し上手く機能し、Queryオブジェクトなどを返却する。CompiledのAPIドキュメントを見て、そのサブクラスなど、コンパイルされたクエリの詳細について学んで欲しい。
ConstColumn[Long]をパラメータに取るtakeやdropを使う場合には気をつけて欲しい。クエリによって計算された他の値に取って代わられるRep[Long]と異なり、ConstColumnはリテラル値かコンパイルされたクエリのパラメータのみを要求する。これは、Slickによって実行される前までに、クエリが実際の値を知っておかなくてはならないためである。
val userPaged = Compiled((d: ConstColumn[Long], t: ConstColumn[Long]) => users.drop(d).take(t))
...
val usersAction1 = userPaged(2, 1).result
val usersAction2 = userPaged(1, 3).result
データの選択、挿入、更新、削除において、コンパイルされたクエリを用いる事ができる。Slick 1.0への後方互換用に、ParametersオブジェクトにflatMapを呼ぶ事で、コンパイルされたクエリを作成する事も可能である。大抵の場合、これはコンパイルされたクエリを1つのfor式で書くのに役立つだろう。
val userNameByID = for {
id <- Parameters[Int]
u <- users if u.id === id
} yield u.first
...
val nameAction = userNameByID(2).result.head
...
val userNameByIDRange = for {
(min, max) <- Parameters[(Int, Int)]
u <- users if u.id >= min && u.id < max
} yield u.first
val namesAction = userNameByIDRange(2, 5).result
Slick 3.0.0 documentation - 08 Schema Code Generation
Permalink to Schema Code Generation — Slick 3.0.0 documentation
スキーマコードの生成
データベーススキーマが既に存在している場合、Slickのコードジェネレータは非常に便利なツールとなる。これはジェネレータ単独で利用する事もできるし、sbtのbuildと組み合わせて必要な全てのSlickのコードを生成する事が出来る。
Overview
デフォルトでは、コードジェネレータは全てのテーブルに対するTableクラスと、対応するTableQueryの値を生成する。列に対応するものは、各カラムを引数に取るケースクラスとして生成される。22より多くのカラムを持つテーブルについては、コードジェネレータは自動的にSlickの実験的な機能であるHListを用いた実装に変更する。これはScalaのタプルサイズ問題を解決する1つの方法である。(Scalaのバージョンが2.10.3以下である場合、コンパイル時間に対する問題を解決するためにHConsが::の代わりに用いられるが、これはScala2.10.4以上では解決されている話だ)
ジェネレータについては、talk at Scala eXchange 2013にも説明があるから、是非見て欲しい。
Standalone use
SlickのコードジェネレータはそのライブラリがSlick本体とは独立して公開されている。sbtプロジェクトにおいては、以下のような記述をビルド定義(build.sbtやproject/Build.scalaなど)に加える事で利用可能となる。
libraryDependencies += "com.typesafe.slick" %% "slick-codegen" % "3.0.0"
Mavenプロジェクトには、以下のような<dependency>を加えて欲しい。
<dependency>
<groupId>com.typesafe.slick</groupId>
<artifactId>slick-codegen_2.10</artifactId>
<version>3.0.0</version>
</dependency>
Slickのコードジェネレータはコマンドラインから、もしくはJavaやScalaからAPIを利用して使う事が出来る。単純な例だと、以下のように実行すれば良い。
slick.codegen.SourceCodeGenerator.main(
Array(slickDriver, jdbcDriver, url, outputFolder, pkg)
)
もしくは、こんな感じに。
slick.codegen.SourceCodeGenerator.main(
Array(slickDriver, jdbcDriver, url, outputFolder, pkg, user, password)
)
引数は、以下のようなものを取る。
- slickDriver Slick driver class, e.g. “slick.driver.H2Driver“
- jdbcDriver jdbc driver class, e.g. “org.h2.Driver“
- url jdbc url, e.g. “jdbc:postgresql://localhost/test“
- outputFolder 生成されたコードを出力するためのフォルダ
- pkg 生成されたコードが置かれるべきScalaのパッケージ名
- user データベースに接続するユーザ名
- password データベースにユーザが接続する際に利用するパスワード
Integrated into sbt
コードジェネレータはsbtで手で実行したり、コンパイル前に毎度実行したりも出来る。slick-codegen-exampleに例があるから参考にして欲しい。
(訳注: tototoshi/sbt-slick-codegenも参考までに)
Generated Code
デフォルトでは、生成されたコードは指定されたフォルダ以下にTables.scalaという名前のファイルで保存される。このファイルは、良い感じにインポート出来るコードを持つobject Tablesを含んでいる。Slickドライバが適切なものになっているかも確認出来る。このファイルにはtrait Tablesも含まれていて、Cakeパターンを用いたい場合にはこちらを利用すると良い。
Warning
生成されたコードを用いる際には、異なるデータベースドライバを誤って混ぜてしまわないように注意して欲しい。デフォルトの
object Tablesはコード生成の際にドライバを用いる。異なるドライバを一緒に使ってしまうと、ランタイムエラーを引き起こす。生成されたtrait Tablesは異なるドライバにより用いられるが、これは現在テストされておらず非公式な使い方となっている。あなたの環境では上手く動かないかもしれない。将来的にこれらについては公式でサポートする予定だ。
Customization
ジェネレータはデータモデルに対しどんなコードも生成出来るよう、様々なメソッドをオーバライドして自由にカスタマイズすることが出来る。簡単なカスタマイズから非常に大きなカスタマイズまで、様々なカスタマイズに対応出来る。Playに対応するフレームワークバインディングを行うだとか、そのような例がある。
This exampleでは、どのようにしてコードジェネレータをカスタマイズするのか、sbtのmulti-projectに対しどのようにセットアップするのか、メインとなるソースに対して、コンパイル前に毎度コードジェネレータをどのようにして実行させるのかを見ることが出来る。
コードジェネレータは、異なるフラグメントに対して最適化された小さなサブジェネレータの階層を構造化して実装されている。サブジェネレータの実装は、個々のファクトリメソッドをオーバーライドすることで、カスタマイズしたものに取り替える事ができる。SourceCodeGeneratorは各々のテーブルのためのサブジェネレータを生成するファクトリメソッドを含んでいる。サブジェネレータはTableクラス自体、エンティティとなるケースクラス、カラム、キー、インデックスなど、様々なものを生成するサブジェネレータを含んでいる。カスタマイズされたサブジェネレータも簡単に同様に扱う事ができる。
様々なサブジェネレータにおいて、Slickのデータモデルに関連する部分はコード生成を実行させる際にアクセスされる。
カスタマイズ可能なオーバーライド出来るメソッド一覧については、api documentationを見て欲しい。
以下にジェネレータをカスタマイズするサンプルを載せる。
import slick.codegen.SourceCodeGenerator
// データモデルを取得する
val modelAction = H2Driver.createModel(Some(H2Driver.defaultTables)) // テーブルのフィルタリングはここで行う
val modelFuture = db.run(modelAction)
// コードジェネレータをカスタマイズする
val codegenFuture = modelFuture.map(model => new SourceCodeGenerator(model) {
// マッピングするテーブルとクラス名をオーバーライド
override def entityName =
dbTableName => dbTableName.dropRight(1).toLowerCase.toCamelCase
override def tableName =
dbTableName => dbTableName.toLowerCase.toCamelCase
// いくつか追加のimportを加える
override def code = "import foo.{MyCustomType,MyCustomTypeMapper}" + "\n" + super.code
// テーブルジェネレータをカスタマイズ
override def Table = new Table(_){
// エンティティクラスの生成を抑制する
override def EntityType = new EntityType{
override def classEnabled = false
}
// カラムジェネレータをカスタマイズ
override def Column = new Column(_){
// 特定のカラムに対して、Scalaの型を変更するようカスタマイズ
// e.g. to a custom enum or anything else
override def rawType =
if(model.name == "SOME_SPECIAL_COLUMN_NAME") "MyCustomType" else super.rawType
}
}
})
codegenFuture.onSuccess { case codegen =>
codegen.writeToFile(
"slick.driver.H2Driver","some/folder/","some.packag","Tables","Tables.scala"
)
}
Slick 3.0.0 documentation - 09 User-Defined Features
Permalink to User-Defined Features — Slick 3.0.0 documentation
ユーザ定義機能
本章では、どのようにしてカスタマイズしたデータ型をSlickのScala APIを通して利用するのか、ということについて説明する。
Scalar Database Functions
もしデータベースシステムがSlickで利用できないメソッドを関数としてサポートしているのならば、SimpleFunctionを通してその関数を利用することが出来る。固定されたパラメータと返り値を用いる1つ・2つ・3つ組といった関数が様々なデータベースに存在している。
// H2データベースでは day_of_week() 関数により、timestampから曜日を取得することが出来る
val dayOfWeek = SimpleFunction.unary[Date, Int]("day_of_week")
...
// 曜日別にグループ化したクエリを用いたクエリは以下のようになる
val q1 = for {
(dow, q) <- salesPerDay.map(s => (dayOfWeek(s.day), s.count)).groupBy(_._1)
} yield (dow, q.map(_._2).sum)
もっと柔軟に型を変形したい場合(複数引数であったり、OptionとNon-Optionの型を使い分けたい)などには、SimpleFunction.applyを使って、適切な型チェックを行うラッパー関数を書く事が出来る。
def dayOfWeek2(c: Rep[Date]) =
SimpleFunction[Int]("day_of_week").apply(Seq(c))
SimpleBinaryOperatorとSimpleLiteralも同じように扱うことが出来る。もっと柔軟な操作を行いたい場合には、SimpleExpressionを用いると良い。
val current_date = SimpleLiteral[java.sql.Date]("CURRENT_DATE")
salesPerDay.map(_ => current_date)
Other Database Functions And Stored Procedures
全てのテーブルを返すようなデータベースの関数を利用したり、ストアドプロシージャを用いたいといった場合には、Plain SQLクエリを用いて欲しい。
Using Custom Scalar Types in Queries
もしカラムに対しカスタマイズした型を適用したいのなら、ColumnTypeを実装して欲しい。アプリケーション特有の型を、データベースにおいて既にサポートされた型へマッピングする事はよくある事例だろう。これを実現するには、MappedColumnTypeを用いて、これに対するボイラープレートを実装するだけで済む。これはドライバをimportする中に含まれており、JdbcDriverのシングルトンオブジェクトから別途importしなくても良い。
// booleanの代数的表現
sealed trait Bool
case object True extends Bool
case object False extends Bool
...
// BoolをIntの1と0にマッピングするためのColumnType
implicit val boolColumnType = MappedColumnType.base[Bool, Int](
{ b => if(b == True) 1 else 0 }, // map Bool to Int
{ i => if(i == 1) True else False } // map Int to Bool
)
...
// この状態で、Boolをビルトインされた型としてテーブルやクエリで利用出来る。
MappedJdbcTypeを使うと、もっと柔軟なマッピングが行える。
もし既にサポートされた型のラッパークラス(ケースクラスやバリュークラスになりえるもの)があるのなら、マクロで生成される暗黙的なColumnTypeを自由に取得出来るMappedToを継承したものを利用する。そのようなラッパークラスは一般的に、型安全でテーブル特有な主キーの型に用いられる。
// カスタマイズされたテーブルのID型
case class MyID(value: Long) extends MappedTo[Long]
...
// MyIDをテーブルのID型としてそのまま用いる -- 特別なボイラープレートは必要ない
class MyTable(tag: Tag) extends Table[(MyID, String)](tag, "MY_TABLE") {
def id = column[MyID]("ID")
def data = column[String]("DATA")
def * = (id, data)
}
Using Custom Record Types in Queries
レコード型は、個々に宣言された型のコンポーネントをいくつか含んだデータ構造として表される。SlickはScalaのタプルをサポートしている以外にも、22個より大きい数のカラム数に対応するためにSlick独自にHListというものを用意している。
カスタマイズされたレコード型(ケースクラス、カスタマイズされたHLists、タプルに似た型など…)を用いるために、Slickに対しどのようにしてクエリと結果型をマッピングするのかというのを伝える必要がある。これに対しては、MappedScalaProductShapeを継承したShapeを用いると良い。
Polymorphic Types (e.g. Custom Tuple Types or HLists)
ポリモーフィックなレコード型は、は要素となる型を抽象化する。つまりここでは、持ち上げられた要素の型と生の要素の型の双方で同じレコード型を用いることが出来るようになる。カスタマイズしたポリモーフィックなレコード型を利用するには、適切な暗黙的Shapeを用意してあげたら良い。
Pairというクラスを使う例は以下のようになる。
// カスタマイズされたレコード型
case class Pair[A, B](a: A, b: B)
...
// PairのためのShape実装
final class PairShape[Level <: ShapeLevel, M <: Pair[_,_], U <: Pair[_,_] : ClassTag, P <: Pair[_,_]](
val shapes: Seq[Shape[_, _, _, _]])
extends MappedScalaProductShape[Level, Pair[_,_], M, U, P] {
def buildValue(elems: IndexedSeq[Any]) = Pair(elems(0), elems(1))
def copy(shapes: Seq[Shape[_ <: ShapeLevel, _, _, _]]) = new PairShape(shapes)
}
...
implicit def pairShape[Level <: ShapeLevel, M1, M2, U1, U2, P1, P2](
implicit s1: Shape[_ <: Level, M1, U1, P1], s2: Shape[_ <: Level, M2, U2, P2]
) = new PairShape[Level, Pair[M1, M2], Pair[U1, U2], Pair[P1, P2]](Seq(s1, s2))
この例における暗黙的なメソッドであるpairShapeは、2つの要素型を持つPairのためのShapeを提供している(個々の要素型のためのShapeは、いつでも利用可能となる)。
これらの定義を用いれば、Slickを利用するどの場所においてもPairをレコード型として利用出来る。
// テーブル定義にPairを利用する
class A(tag: Tag) extends Table[Pair[Int, String]](tag, "shape_a") {
def id = column[Int]("id", O.PrimaryKey)
def s = column[String]("s")
def * = Pair(id, s)
}
val as = TableQuery[A]
...
// カスタマイズされた型のデータを挿入する
val insertAction = DBIO.seq(
as += Pair(1, "a"),
as += Pair(2, "c"),
as += Pair(3, "b")
)
...
// クエリからPairを返却してもらう
val q2 = as
.map { case a => Pair(a.id, (a.s ++ a.s)) }
.filter { case Pair(id, _) => id =!= 1 }
.sortBy { case Pair(_, ss) => ss }
.map { case Pair(id, ss) => Pair(id, Pair(42 , ss)) }
// returns: Vector(Pair(3,Pair(42,"bb")), Pair(2,Pair(42,"cc")))
Monomorphic Case Classes
カスタマイズされたケースクラスが単一的なレコード型としてしばしば用いられる(要素型が固定されたレコード型など)。Slickにおいてこのようなケースクラスを用いるためには、レコードの生の値を取り扱うケースクラスを定義するのに加えて、持ち上げられたレコードの値を取り扱うケースクラスを定義する必要がある。
カスタマイズしたケースクラスのShapeを提供するためには、CaseClassShapeを用いると良い。
// 2つのケースクラスを用意
case class LiftedB(a: Rep[Int], b: Rep[String])
case class B(a: Int, b: String)
...
// 定義したケースクラスに対するマッピング
implicit object BShape extends CaseClassShape(LiftedB.tupled, B.tupled)
...
class BRow(tag: Tag) extends Table[B](tag, "shape_b") {
def id = column[Int]("id", O.PrimaryKey)
def s = column[String]("s")
def * = LiftedB(id, s)
}
val bs = TableQuery[BRow]
...
val insertActions = DBIO.seq(
bs += B(1, "a"),
bs.map(b => (b.id, b.s)) += ((2, "c")),
bs += B(3, "b")
)
...
val q3 = bs
.map { case b => LiftedB(b.id, (b.s ++ b.s)) }
.filter { case LiftedB(id, _) => id =!= 1 }
.sortBy { case LiftedB(_, ss) => ss }
...
// returns: Vector(B(3,"bb"), B(2,"cc"))
このメカニズムは、<> オペレータを用いたクライアントサイドマッピングの代わりとして用いられている。これにはすこしばかりボイラープレートが必要になるが、生のレコードと持ち上げられたレコードの双方において同じフィールド名を持たせてくれる。
Combining Mapped Types
以下の例では、マッピングされたケースクラスと、他でマッピングされたケースクラスでマッピングされたPairの2つを組み合わせている。
// 複数のマッピングされた型を組み合わせている
case class LiftedC(p: Pair[Rep[Int],Rep[String]], b: LiftedB)
case class C(p: Pair[Int,String], b: B)
...
implicit object CShape extends CaseClassShape(LiftedC.tupled, C.tupled)
...
class CRow(tag: Tag) extends Table[C](tag, "shape_c") {
def id = column[Int]("id")
def s = column[String]("s")
def projection = LiftedC(
Pair(column("p1"),column("p2")), // (cols defined inline, type inferred)
LiftedB(id,s)
)
def * = projection
}
val cs = TableQuery[CRow]
...
val insertActions2 = DBIO.seq(
cs += C(Pair(7,"x"), B(1,"a")),
cs += C(Pair(8,"y"), B(2,"c")),
cs += C(Pair(9,"z"), B(3,"b"))
)
...
val q4 = cs
.map { case c => LiftedC(c.projection.p, LiftedB(c.id,(c.s ++ c.s))) }
.filter { case LiftedC(_, LiftedB(id,_)) => id =!= 1 }
.sortBy { case LiftedC(Pair(_,p2), LiftedB(_,ss)) => ss++p2 }
...
// returns: Vector(C(Pair(9,"z"),B(3,"bb")), C(Pair(8,"y"),B(2,"cc")))
Slick 3.0.0 documentation - 10 Plain SQL Queries
Permalink to Plain SQL Queries — Slick 3.0.0 documentation
Plain SQLクエリ
もしかすると、高レベルに抽象化されてサポートされたオペレーションに対し、SQLコードをそのまま書きたいといった要求があるかもしれない。そのような場合には、低レベルなJDBCのAPIを用いるのではなく、Slickが提供するScalaベースの Plain SQL を利用して欲しい。
Note
本章の残りでは、Slick Plain SQL Queries templateをベースに説明を行う。Activatorからテンプレートを落としてきて、直接編集したり実行しながら読んでみて欲しい。
Scaffolding
データベースのコネクションは、いつもと同じように開かれる。全ての Plain SQL DBIOActions内で実行される。これは複数のアクションを組み合わせたものする事も可能である。
String Interpolation
Slickの Plain SQL はsql、sqlu、tsqlという文字列の補間(string interpolation)を通して組み立てることが出来る。これらはSlickドライバからapi._をインポートする事で利用可能となる。
import slick.driver.H2Driver.api._
最も簡単な使用法としては、以下のようなメソッドの中で利用しているように、sqluの中にSQLコードをそのまま書いてしまうことだ。
def createCoffees: DBIO[Int] =
sqlu"""create table coffees(
name varchar not null,
sup_id int not null,
price double not null,
sales int not null,
total int not null,
foreign key(sup_id) references suppliers(id))"""
...
def createSuppliers: DBIO[Int] =
sqlu"""create table suppliers(
id int not null primary key,
name varchar not null,
street varchar not null,
city varchar not null,
state varchar not null,
zip varchar not null)"""
...
def insertSuppliers: DBIO[Unit] = DBIO.seq(
// Insert some suppliers
sqlu"insert into suppliers values(101, 'Acme, Inc.', '99 Market Street', 'Groundsville', 'CA', '95199')",
sqlu"insert into suppliers values(49, 'Superior Coffee', '1 Party Place', 'Mendocino', 'CA', '95460')",
sqlu"insert into suppliers values(150, 'The High Ground', '100 Coffee Lane', 'Meadows', 'CA', '93966')"
)
sqlu補間子は、結果の代わりに列の数を返すDMLステートメントとして用いられる。それゆえ、sqluを用いた場合は返り値の型がDBIO[Int]となる。
クエリに注入される変数や表現は、クエリ文字列の中でバインド変数などで表される。クエリ文字列に直接変数を入れることはしない。このような対応は、SQLインジェクションをなくすためにある。以下の例を見て欲しい。
def insert(c: Coffee): DBIO[Int] =
sqlu"insert into coffees values (${c.name}, ${c.supID}, ${c.price}, ${c.sales}, ${c.total})"
このメソッドにより生成されるSQLステートメントは、常に同じものになる。
insert into coffees values (?, ?, ?, ?, ?)
この種のコードに役立つ便利なDBIO.sequenceコンビネータは以下のように利用できる。
val inserts: Seq[DBIO[Int]] = Seq(
Coffee("Colombian", 101, 7.99, 0, 0),
Coffee("French_Roast", 49, 8.99, 0, 0),
Coffee("Espresso", 150, 9.99, 0, 0),
Coffee("Colombian_Decaf", 101, 8.99, 0, 0),
Coffee("French_Roast_Decaf", 49, 9.99, 0, 0)
).map(insert)
...
val combined: DBIO[Seq[Int]] = DBIO.sequence(inserts)
combined.map(_.sum)
与えられた順序でデータベースのI/Oアクションを直列に実行するシンプルなDBIO.seqとは異なり、DBIO.sequenceは個々のアクションの結果を保護するために、Seq[DBIO[T]]をDBIO[Seq[T]]へ変換する。これは挿入時に影響のあった列の数を数え上げる際などに用いられている。
Result Sets
以下のコードでは、ステートメントにより得られた結果を返却するsql補間子を利用している。sql補間子自身はDBIOの値を生成したりはしない。これは、.asというメソッドを返り値となる型を組み合わせて呼び出す必要がある。
sql"""select c.name, s.name
from coffees c, suppliers s
where c.price < $price and s.id = c.sup_id""".as[(String, String)]
この結果の型は、DBIO[Seq[(String, String)]]となる。asを呼び出す際には、結果から要求する型の値を抽出するGetResultパラメータを暗黙的に必要としている。基本的なJDBCの型やOption、タプルなどに対するGetResultは予め定義されている。それ以外の型に対するGetResultは、各自で定義して欲しい。
// 適当なケースクラス
case class Supplier(id: Int, name: String, street: String, city: String, state: String, zip: String)
case class Coffee(name: String, supID: Int, price: Double, sales: Int, total: Int)
...
// 結果を抽出するためにGetResult
implicit val getSupplierResult = GetResult(r => Supplier(r.nextInt, r.nextString, r.nextString,
r.nextString, r.nextString, r.nextString))
implicit val getCoffeeResult = GetResult(r => Coffee(r.<<, r.<<, r.<<, r.<<, r.<<))
GetResult[T]はPositionedResult => Tという関数の単なるラッパーにすぎない。Supplierのための暗黙的なGetResultは、列からIntかStringの値を読み出すために、明示的なPositionedResultを用いている。2個めのCoffeeの例では、期待する型を自動的に導出しようと試みる<<というショートカットメソッドを利用している(コンストラクタの呼び出しに対して明らかに型が導出出来る場合にのみ利用可能)。
Splicing Literal Values
パラメータはSQLステートメントに対してバインド変数を用いて挿入されるわけだが、動的に生成されたSQLコードを呼び出す際などでは、もしかすると直接ステートメントの中にリテラルを書く必要が生じるかもしれない。このような場合には以下の例のように、全ての補間子の中で$の代わりに#$を用いて変数をバインドしてあげれば良い。
val table = "coffees"
sql"select * from #$table where name = $name".as[Coffee].headOption
Type-Checked SQL Statements
今まで見てきた補間子は、SQLステートメントを実行時に構築する。これはステートメントを構築する安全で簡単な方法となっている一方、単なる埋め込み文字列にしかならない。もしステートメントにシンタックスエラーがあったり、データベースとScalaのコードに何かしら型の違いがあったする場合にも、コンパイル時に検出が出来なく、非常に残念である。そのような場合には、sql補間子の代わりにtsql補間子を使う事を検討してみて欲しい。
def getSuppliers(id: Int): DBIO[Seq[(Int, String, String, String, String, String)]] =
tsql"select * from suppliers where id > $id"
tsqlは.asを呼び出す必要無しに、直接DBIOActionを生成する。
tsqlを利用する際は、SQLコンパイラをデータベースにアクセスさせるために、コンパイル時に解決できる設定を提供してあげる必要がある。これはStaticDatabaseConfigアノテーションを利用して明示する。
@StaticDatabaseConfig("file:src/main/resources/application.conf#tsql")
上の例だと、application.confというファイルにおける、"tsql"というパスを指し示しており、ここにはDatabaseの設定だけではなく、StaticDatabaseConfigオブジェクトのための適切な設定を記述しなくてはならない。
Note
パスを省いたり、URLのフラグメントのみを指定したりすると、クラスパスにある中から
application.confを見つけようとする。また、resource:というURLスキーマを利用しても良いが、いずれにしても実行時のクラスパスと異なり、コンパイラ時のクラスパスからそれらは見えるようにする必要がある。ビルドツールによっては設定が出来ないかもしれないため、基本的にはfile:のURLスキーマで相対パスを指定するのが良い。
実行時に、設定のされたDatabaseConfigを取得させても構わない。
val dc = DatabaseConfig.forAnnotation[JdbcProfile]
import dc.driver.api._
val db = dc.db
ここでは、基本的なapi._というインポートとDatabaseを利用している。同じ設定を用いさせることは特に強制しておらず、SlickドライバとDatabaseを他の方法で実行時に渡しても良いし、コンパイル時のチェックのみにStaticDatabaseConfigを利用するといった方法も1つの選択肢として考えられる。
Slick 3.0.0 documentation - 11 Coming from ORM to Slick
Permalink to Coming from ORM to Slick — Slick 3.0.0 documentation
ORMからSlickを利用する人へ
Introduction
Slickは、Hibernateや他のJPAベースのプロダクトのようなORM(object-relational mapper)では無い。SlickはORMのようにデータを永続化させるソリューションの1つであり、いくつかのコンセプトは共有しつつも、大きな違いがいくつかある。本章ではSlickのメリットについての理解を手助けしつつ、ORMとの違いについて順に説明する。object-relationalなものに対して言及される様々な問題(object-relation-impedance mismatch)をSlickは上手く取り扱っていることについても説明したい。
SlickはFRM(functional-relational mapper)である、と表現されるのが良い。Slickはイミュータブルなコレクションをもとにして関係データを取り扱っており、より自由なクエリ生成とうまくコントロールされた副作用処理に対し、特に焦点を当てた作りになっている。ORMでは一般的にミュータブルなオブジェクトグラフをむき出しにし、read-・write-cachesのような副作用や、ハードコードサポート(継承を利用したユースケースや関連テーブルを通した関連の取得など)を利用してしまっている事が多い。ORMではオブジェクトグラフの永続化に焦点を当てている一方、Slickは関連データストアにアクセスする最も良い方法に焦点を当てている。
ORMはオブジェクト指向言語からデータベースを利用する際には、自然なアプローチをとっている。ORMではデータがメモリ内に残っていたとしても、オブジェクトグラフを部分的に永続化させようとする。オブジェクトは編集可能、関連も変更が可能であり、オブジェクトグラフは色々と状態が変化する。実のところ、このようなものに対して正確に保存をするのは簡単ではない。それゆえこの問題を object-relation impedance mismatchと呼んでいる。これはORMの実装をを難しくさせている所以であり、ほんの少し難しいケースに対しても複雑化してしまうこともある。一方でSlickはオブジェクトグラフをむき出しにしたりはしていない。SlickはSQLや関連モデルからインスパイアされているし、型安全なScalaの特徴を利用しつつも、大抵の場合コンセプトはだいたい同じものになっている。データベースクエリはScalaの制限されたイミュータブルな、純粋関数のサブセットを用いて表現されている。Scala側からも代わりのものとしてfirst-class SQL supportを提供している。
実のところ、ORMはそれ自体が挑戦しようと試みている事に対する概念的な課題にしばしば直面する。これはORMが複雑なせいであり、実装上の課題であったり、使用上の課題であったりもする。以下では、ORMについての特徴と、なぜ代わりにSlickを用いる事を推奨するのかについて述べる。初めに、どのようにしてオブジェクトグラフとうまく付き合っていくかについて説明し、それからSlickがどのようにして取り組んでいるかをその特徴とユースケースを主に述べていく。
Configuration
いくつかのORMでは外部の設定ファイルを用いる。Slickは少しのScalaのコードを用いて設定を行う。データベースに接続する方法についての情報をSlickに提供し、Slickにクエリに対する型チェックを行いたいのならば、database-schemaを手で書くor自動生成させる。外部キーを用いる関連の定義といったようなものも、再利用可能な抽象メソッドを利用しつつ、基本的なScalaのコードで記述する事が出来る。
Mapping configuration.
以下の例では、このようなデータベーススキーマを用いる。
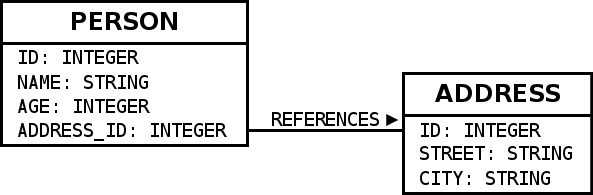
このスキーマをSlickで利用する際は、以下のようなコードを記述すれば良い。
type Person = (Int,String,Int,Int)
class People(tag: Tag) extends Table[Person](tag, "PERSON") {
def id = column[Int]("ID", O.PrimaryKey, O.AutoInc)
def name = column[String]("NAME")
def age = column[Int]("AGE")
def addressId = column[Int]("ADDRESS_ID")
def * = (id,name,age,addressId)
def address = foreignKey("ADDRESS",addressId,addresses)(_.id)
}
lazy val people = TableQuery[People]
...
type Address = (Int,String,String)
class Addresses(tag: Tag) extends Table[Address](tag, "ADDRESS") {
def id = column[Int]("ID", O.PrimaryKey, O.AutoInc)
def street = column[String]("STREET")
def city = column[String]("CITY")
def * = (id,street,city)
}
lazy val addresses = TableQuery[Addresses]
テーブルはケースクラスにマッピングされる。このコードは自動生成しても手で書いても良い。
ORMではコンフィグファイルの中でマッピングの仕様について記述を行う。Slickでは、上記の例のようにScalaの型として仕様を提供してあげる事ができ、型安全なSlickのクエリを用いる事ができる。違いとして、Slickのマッピングは概念上非常にシンプルだ。単にテーブルの情報を記述するだけでよく、列に対するマッピングを行うケースクラスやその他のファクトリや抽出子はオプショナルにすぎない。外部キーの情報は持たせる事が出来るものの、関連やその類の情報については保持しない。その代わりに再利用可能な部分的なクエリを用いたマッピングなども行える。
Navigating the object graph
Using plain old method calls
本章では、厳格vs遅延、もしくは義務的or宣言的について考えていきたい。一般的なORMの特徴の一つとして、オブジェクトグラフが、まるでメモリ上に存在しているかのように扱える、ということがある。関連メンバのような関連するオブジェクトについては、必要に応じてアドホックにデータがデータベースから読み込まれる。メモリ上にあるかのように表現するために、ORMは関連メンバに対する呼び出しを途中でフックしたりして、必要なデータを得るために、データベースクエリをその途中で実行したりしている。以下のORMっぽい例を見てみよう。
val people: Seq[Person] = PeopleFinder.getByIds(Seq(2,99,17,234))
val addresses: Seq[Address] = people.map(_.address)
データを取得するのに何回データベースとやり取りをする必要があるのだろうか?実際ORMのコレクション風APIを学ぶ際には、この質問に何度も直面することになるだろう。普通に考えると、このORMはgetByIdsの際にデータベースと一度やり取りを行い、Personに関する結果を返す。それからScalaのListのメソッドであるmapを使い、各Personからaddressを取得するために.map(_.address)を呼ぶ。ORMはこのmapのループの前にaddressが何度も呼ばれる事を通常知らない。その結果、各Personのaddressを取得するために何度もデータベースとやり取りをしなくてはならなくなるし、データベースのやり取りのコストを考えると、非常に非効率である(n+1問題)。この問題を解決するためには、以下の例のように、ORMに将来的にデータが必要になる旨を事前に伝えてあげることで、複数回のデータベース呼び出しを集約により効率化させる事ができる。
// 関連する`address`をロードしておくことをORMに事前に伝える
val people: Seq[Person] = PeopleFinder.getByIds(Seq(2,99,17,234)).prefetch(_.address)
val addresses: Seq[Address] = people.map(_.address)
ここでは仮のORMの中でprefetchメソッドにより各Personのaddressを予めロードしている。結果、データベースとのやり取りは1度か2度に収まる。addressの情報はORMの管理下にキャッシュされる。続く.map(_.address)では、キャッシュされたメモリ上の値からデータを得る事ができる。もちろんこれは2度もaddressへのマッピングを教えてあげる必要があるため無駄があるし、もしprefetchを忘れた場合には、非効率な処理になってしまうだろう。ORMにもよるが、prefetchの方法として外部の設定を用いるか、上記の例のようにインラインで記述する方法がある。
Slickは関連するデータを取得するのに異なる方法をとっている。同じような処理には、以下のような記述を行う。型アノテーションは必要無いが、分かりやすさのためにここでは記述している。
val peopleQuery: Query[People,Person,Seq] = people.filter(_.id inSet(Set(2,99,17,234)))
val addressesQuery: Query[Addresses,Address,Seq] = peopleQuery.flatMap(_.address)
見ての通り、この例はまさにScalaのコレクション操作と同じであり、違いは返り値がQuery型になるだけだ。この時点ではSlickは、データを取得する上で必要になるSQLを作るために必要な計画を練っているだけで、データベースに対しアクセスは行わない。上記の例は、まだ一度もデータベースにはアクセスしていない。実際にデータを取得するには、.resultを用いてdatabase Actionにクエリをコンパイルさせ、Databaseオブジェクトにrunしてもらう。
val addressesAction: DBIO[Seq[Address]] = addressesQuery.result
val addresses: Future[Seq[Address]] = db.run(addressesAction)
結果の取得には、たった1つのクエリのみが実行される。これはデータベースへのアクセスを行う箇所を明らかにしているし、非常に理に適っている。
Slickの例を見ての通り、Slickではオブジェクトグラフ(i.e. results)を直接操作したりはしない。その代わりにSlickは、データベースアクセス無しに効率的なクエリを発行出来るよう事前にクエリを組み立て、オブジェクトグラフを操作している。Slickでは実際に必要になるまでクエリの組立を遅延させ、Database.runの呼び出しによりクエリを発行させるのである。
ORMにおいてオブジェクトグラフを直接操作することは、あまりに早い状態でクエリを発行してしまうため問題になりやすい。そのためSlickではこのような機能を外した。ORMはこの問題に取り組むにあたり、しばしば宣言的なクエリ言語を用いて問題を解決しようとしている。これはSlickの動作とよく似たものになっている。
Query languages
ORMはしばしばJPAのSQLやCriteria APIのような宣言的なクエリ言語を用いている。SQLやSlickのように、これらのクエリ言語は実行すること無しにクエリを表現する事が可能であり、クエリを実行するには明示的な処理を必要とする。
String based embeddings
ここではHQLの例を出すが、一般的にこのようなクエリ言語では、SQLは文字列としてプログラムに埋め込まれている。HQLの例を見てみよう。
val hql: String = "FROM Person p WHERE p.id in (:ids)"
val q: Query = session.createQuery(hql)
q.setParameterList("ids", Array(2,99,17,234))
大抵の言語において、コンパイラを変更せずに任意の言語を埋め込むのには文字列を使うのが最も簡単である。シンプルである一方、この種の埋め込みには大きな制限がかかる。
1つの大きな問題としては、このようなツールには埋め込まれた言語や、任意の文字列としてクエリを扱う事に対する知識を持たせる事が出来ない。ホストされた言語のコンパイラやインタプリタは記述の間違いを発見したりは出来ないし、もしクエリが期待する型とは異なる型を返しても間違いを検出出来ない。1つの解決法としては、IDEによりシンタックスハイライトやコード補完、インラインのエラーなどを表示させる、といった方法があげられる。
また、大きな問題として、この種の言語では再利用が難しい。クエリの一部分を再利用するために文字列を結合したいと考えるかもしれない。上記のHQLの例で、idによるフィルタリングの機能を再利用可能なものとして扱いたいとする。Personテーブル以外にもAddressテーブルでその機能を使いたくても、これは非常に扱うのが難しいものになってしまう。
Javaはその他多くの言語において、文字列は正確なクエリ言語を埋め込む唯一の方法になっている。次のセクションを見て、Scalaがいかに柔軟かを確認して欲しい。
Method based APIs
埋め込み言語にとって柔軟性を得るものとして、その他のアプローチとして、ホストされた言語の拡張機能を用いて同様の機能を利用する方法があげられる。JavaやScalaのようなオブジェクト指向言語はオブジェクトやメソッドのAPI定義を通した拡張を許可している。JPAのCriteria APIはこの概念を利用しており、Slickも同様に利用している。これは埋め込まれた言語を部分的に理解するために、ホストされた言語の機能を利用している。Criteria Queriesを用いた例を見てみよう。
val id = Property.forName("id")
val q = session.createCriteria(classOf[Person])
.add( id in Array(2,99,17,234) )
埋め込みを利用するメソッドはクエリを部分的に利用可能なものへと変化させる。idによるフィルタリングのみの機能を生成するのも容易い。
def byIds(c: Criteria, ids: Array[Int]) = c.add( id in ids )
...
val c = byIds(
session.createCriteria(classOf[Person]),
Array(2,99,17,234)
)
もちろん上の例は取るに足らない例ではあるが、より複雑なクエリを合成する上で、このメソッドは既に役立つものになっている。
JPAのCriteria APIのようなJava APIは、Scalaのようにオペレータの機能をオーバーロードしたりは出来ない。これはクエリを表現する際のよく似たコードを減らす。例として、5歳より若いか65歳より歳のいった人を取得するクエリを考えてみよう。
val age = Property.forName("age")
val q = session.createCriteria(classOf[Person])
.add(
Restrictions.disjunction
.add(age lt 5)
.add(age gt 65)
)
Scalaはオペレータをオーバーロード出来るため、Slickでは以下のような記述が可能になり、クエリはより簡潔なものになる。
val q = people.filter(p => p.age < 5 || p.age > 65)
Scalaのオーバーロードには、Slickにも影響を与えるものとして、いくつか制限があった。Slickでは、クエリの中で==は===に、!=は=!=と記述しなくてはならない。また、文字列結合にも+の代わりに++を用いなくてはならない。さらに、ifという予約後をオーバーロードする事も出来ない。Slickでは代わりのものとして、DSL for SQL case expressionsを提供している。
前述した通り、Slickでは、クエリを実行しないクエリを記述するためだけのものとして、プレースホルダ構文も扱える。以下の例では分かりやすさのために型アノテーションを書いているが、実際には書く必要はない。
val q = (people: Query[People, Person, Seq]).filter(
(p: People) =>
(
((p.age: Rep[Int]) < 5 || p.age > 65)
: Rep[Boolean]
)
)
Queryはコレクション風のクエリ表現を指定する。PeopleはPersonのテーブルのために定義されたSlickのTableのサブクラスである。値が列を表すプロトタイプとして用いられることに混乱してしまうかもしれない。個々のカラムを表すRepのメンバーもある。filterをするために、いくつかのRep[Int]を用いてRep[Boolean]を得ている。内部的にSlickは、オペレーション内容を表すSQLコードを生成するのに用いられるツリーを作成している。Slickはしばしばこのような表現木(持ち上げられた表現として、プレースホルダーの値を含んだもの)の生成プロセスを呼び出す。これ故にSlickのクエリインターフェスの1つを lifted embedding と呼んでいる。
Scalaが型安全であるのは非常に重要な事である。例として、SlickはRep[String]のために.substringというメソッドをサポートしている(Rep[Int]には使えない)。これはJavaやCriteria QueriesのようなJava APIにおいては利用不可能なものである。Scalaでは暗黙的な表現を通したメソッド拡張に基づく型パラメータを利用する事で、サポートが可能となった。ScalaコンパイラのようなツールやIDEが、コードを正確に理解したりチェックやサポートを行ってくれるのを手助けしてくれる。
Slickのようなクエリ言語において、Scalaのコレクション操作のシンタックスシュガーであるfor式が非常に役立つ。上の例は、for式を使う事で、以下のように書き換える事が出来る。
for( p <- people if p.age < 5 || p.age > 65 ) yield p
Scalaのfor式は、SQLやORMのクエリ言語によく似たものになる。一方で、ソートやグルーピングのような幾つかの操作のためのシンタックスサポートが欠けている。
( for( p <- people if p.age < 5 || p.age > 65 ) yield p ).sortBy(_.name)
シンタックスの制限があるにも関わらず、for式は複数のinner joinを利用する時などに非常に便利なものとなる。
先に記述したような、Criteria QueriesのようなメソッドベースなクエリAPIの問題は、ORMのクエリ言語にある概念上の制限とは異なる事を胸に留めといて欲しい。ScalaのORMはSlickのようなクエリ言語にオファーしても良いし、そうすべきであると考えている。快適にクエリを合成出来る事は、コードの再利用性に大きなメリットをもたらす。これは多くの開発者にとってSlickのお気に入りの機能になるのではないだろうか。
Macro-based embeddings
Scalaのマクロは埋め込みクエリのためのもう一つのアプローチとなる。文字列として埋め込まれたクエリをコンパイル時にチェックすることが可能になる。QueryやRepに関わるSQLへのプレースホルダを使う事無しにScalaのコードを変換する事が可能になる。双方のアプローチはSlickで利用する事が出来るが、まだ万全の準備ができているわけではない。クエリ言語のためにマクロを用いているデータベースライブラリは他にも存在している。
Query granularity
ORMを用いると、データをロードする際にオブジェクトを取り扱ったり、最も小さい粒度として列を補完したりすることは凡そ亡くなる。これはフレームワークによって制限されているわけではないが、慣例としてそのように扱われている。Slickを用いると実際に欲しいデータのみを取得する事が簡単になる。Slickでは列をクラスに対してマッピング出来るが、そのような機能を使わないことでより効率的なクエリを実行出来る。その時その時に必要なデータのみを取り出すようなクエリを扱える。もしpersonの名前と年齢のみが必要なら、以下のようにする事でタプルを返すことができる。
people.map(p => (p.name, p.age))
このような記述により、正確に欲しいデータのみを取得することが可能になる。
Read caching
Slickはクエリの結果をキャッシュしない。Slickを扱うのは生のJDBCを扱う事と等しいようなもんだ。多くのORMではキャッシュの読み書きを行う。キャッシュは一種の副作用である。これらは、時に理解を難しくさせる。キャッシュにより保存されたデータとそのライフタイムを扱う事は難しい。
PeopleFinder.getById(5)
ORMの例においては、ここではデータベースもしくはキャッシュから値を取り出している。どのような処理が生じたのかが明らかになっていない。Slickではデータベースとのやり取りは、クエリを実行させる処理を呼び出す必要があるので、非常に明確だ。Slickはオブジェクトへのアクセスに干渉したりもしない。
db.run(people.filter(_.id === 5).result)
Slickは毎度データベースのデータに対して、矛盾のないイミュータブルなスナップショットを返す。もし複数クエリに対する永続性を保証したいのなら、トランザクションを用いれば良い。
Writes (and caching)
多くのORMでは書き込み操作はパフォーマンスのためにキャッシュを経由する。
val person = PeopleFinder.getById(5)
person.name = "C. Vogt"
person.age = 12345
session.save
上の仮ORMのレコードは、オブジェクトを変更し、.saveメソッドを呼ぶことでデータベースとのやり取りを1度だけ行いデータを同期させている。Slickでは以下のような記述が可能だ。
val personQuery = people.filter(_.id === 5)
personQuery.map(p => (p.name,p.age)).update("C. Vogt", 12345)
Slickは宣言的な変換を内包してしまっている。オブジェクトの個々の値を順に変更するのではなく、全ての変更を同時に行い、キャッシュを通さずにデータベースとのやり取りを1度だけ行う。Slickの新規ユーザにとって、このシンタックスは混乱を招くかもしれない。しかし実際にはこれはよく整理されたシンタックスになっている。Slickはクエリの選択、挿入、更新、削除に対するシンタックスを一体化している。上記personQueryはデータを取得するために単なる選択用クエリに過ぎない。実際には、クエリにより特定されたカラムの更新を行うためにこの選択用クエリは用いられる。personQueryは列の削除にもそのまま使える。
personQuery.delete // deletes person with id 5
データを挿入するには、代入するカラムを選択した後に、個々のカラムに対する値を挿入してあげたら良い。
people.map(p => (p.name,p.age)) += ("S. Zeiger", 54321)
Relationships
ORMは一対多関連、多対多関連に対しハードコードされたサポートを提供している。関連に関しては設定の中でセットアップが行われる。一方、SQLでは各クエリに対しjoinを用いる事で関連を取得する。joinを用いることで柔軟な記述が可能になる。Slickでは両方の記述方法をより良い形で提供している。SlickのクエリはSQLと同じぐらい柔軟であるのに加えて、組み合わせ可能なものになっている。join条件に関わる部分的なクエリを定義する事もできるため、言語レベルの抽象化が可能になる。Slickがこの種のユースケースのためにハードコードサポートする必要は全く無い。あなたは、一対多、多対多関連や複数テーブルを跨ぐ関連の取得に対しても、任意のユースケースに対して簡単に実装が行える。
PersonとAddressに対する例は以下のようになる。
implicit class PersonExtensions[C[_]](q: Query[People, Person, C]) {
// 住所に対する関連のマッピング
def withAddress = q.join(addresses).on(_.addressId === _.id)
}
...
val chrisQuery = people.filter(_.id === 2)
val stefanQuery = people.filter(_.id === 3)
...
val chrisWithAddress: Future[(Person, Address)] =
db.run(chrisQuery.withAddress.result.head)
val stefanWithAddress: Future[(Person, Address)] =
db.run(stefanQuery.withAddress.result.head)
Slickを初めて使うユーザがよくする質問として、どのようにして関連の結果を利用するのか、といったことがあげられる。ORMではおそらくこんな感じで書けるのだろう。
val chris: Person = PeopleFinder.getById(2)
val address: Address = chris.address
以前に説明したように、Slickはデータがメモリ上にあるかのようにオブジェクトグラフを操作出来るようにはしていない。関連を直接操作するのではなく、データベースにアクセスする前に、関連データを取得するような別のクエリを記述して欲しい。
val chrisQuery: Query[People,Person,Seq] = people.filter(_.id === 2)
val addressQuery: Query[Addresses,Address,Seq] = chrisQuery.withAddress.map(_._2)
val address = db.run(addressQuery.result.head)
上の例では型アノテーションを記述しているが、これは普段の記述には必要無く、取り除くことで見通しの良いコードになるだろう。そしてデータベースへのアクセスがどこで発生するのかについて非常に分かりやすいものになっている。
他のSlick初心者の中には、どのようにしたらSlickで以下のような記述が出来るのか、といった疑問を考える人もいるかもしれない。
case class Address( … )
case class Person( …, address: Address )
ここにはPersonがAddressを必要とすることがハードコードされてしまうという問題がある。そのような情報無しにデータが読み込まれてはならない。もしそのような挙動を許してしまったなら、正確にデータを読み込ませる事を上手くユーザの管理下に置かせるという、Slickの哲学に反するものになってしまう。1つのテーブルからタプルやケースクラスへのマッピングを定義しているが、関連オブジェクトへのリファレンスをオブジェクトに持たせる事はSlickでは行っていない。その代わりに、2つのテーブルを結合させ、それらの結果をタプルもしくは結果の合わさったケースクラスのインスタンスとして返すメソッドを記述することができる。これは関連を明示するだけものであり、クラスの1つに強く紐付いたものにはなっていない。
val tupledJoin: Query[(People,Addresses),(Person,Address), Seq]
= people join addresses on (_.addressId === _.id)
...
case class PersonWithAddress(person: Person, address: Address)
val caseClassJoinResults = db.run(tupledJoin.result).map(_.map(PersonWithAddress.tupled))
それ以外のアプローチとして、関連オブジェクトへの参照を表すOption型のメンバ変数をクラスに定義させることも出来る。Noneは関連オブジェクトがまだ読み込まれていない事を表す。しかしこれはタプルやケースクラスを用いても型安全性に欠けるものになっている。なぜなら、関連オブジェクトが読み込まれたとしても厳格なチェックが出来ないためである。
Modifying relationships
ORMを用いて関連を操作する際に、関連オブジェクトのミュータブルなコレクションを用いて挿入や削除を行うといったことがしばしば見受けられる。変更は即座にデータベースへ書き込まれる、もしくはキャッシュに記録された後にまとめて書き込まれる。ステートフルなキャッシュやミュータブルなオブジェクトを扱うのを避けるために、SlickはSQLのように外部キーを用いた関連操作を提供している。関連の変更は、単に普通のフィールドを変更するかのように、外部キーのフィールドを新しいidへ更新する事で行う。良いことに、これはメモリにロードされていないオブジェクトの関連を、作成したり取り除いたりも出来るようになっている。単にidを扱うだけで十分なのである。
Inheritance
Slickは任意のオブジェクトグラフを押し付けたりはしない。Scalaに統合されたナイスな関連データモデルを提供しているだけである。関連スキーマは継承を含んでたりはしない。一般的に継承は、ルールに沿うような関連に簡単に取って代わられる。fooはbarであるというのは、barという役割を持つfooを考えるのと同じである。Slickはクエリ合成やクエリの抽象化を許可しており、継承風のクエリスニペットを実装するのは容易いし、再利用のための関数にも用いやすい。Slickは枠外の機能を提供していないが、その柔軟さゆえにあなた自身のコードの中で問題に合うような記述法等を自由に記述しても良い。
Code-generation
上記のようなコンセプトの多くは、Scalaのコードを用いてコードの重複を避けるような抽象化が行われる。しかし、もしかするとあなたはScalaの型システムの抽象能力の限界に達してしまうかもしれない。コード生成はこの課題に対する解決法の1つとして提供されている。Slickは非常に柔軟で様々なカスタマイズも行えるcode generatorを提供している。コード生成機能はデータベースのメタデータを用いて動作する。Slickの型、関連情報を生成するのに必要な独自のメタデータを組み合わせる事も出来る。詳しくはScala Days 2014のトークを見て欲しい。
Slick 3.0.0 documentation - 12 Coming from SQL to Slick
Permalink to Coming from SQL to Slick — Slick 3.0.0 documentation
SQLからSlickを利用する人へ
JDBC/SQLを利用していて、Slickに移ってきた場合には躓くことなく学ぶ事が出来るだろう。Slickはコネクションハンドリング、結果の取得、クエリ言語の利用という事についてより良いAPIを備えている。さらに文字列クエリを書くよりも、Scalaを通してより良い記述が行えるようなものを統合している。SQLを知っていてSlickを学ぼうと考えている開発者にとっての主な障壁は、SQLとScalaのコレクションの間にある、よく似た操作に対するセマンティックの違いのみであろう。本章ではこれらの違いについての概要をみていく。概念的な違いを考えた後に、SQL操作とSlickの操作の比較を例を通して説明していく。SlickのAPIに関する詳細な説明については、クエリについての章やthe Scala collections APIにあるメソッドを見て欲しい。
Schema
本章ではこのようなデータベーススキーマを例に説明を行う。
Slickで上記スキーマを記述した際には、以下のように定義出来る。
type Person = (Int,String,Int,Int)
class People(tag: Tag) extends Table[Person](tag, "PERSON") {
def id = column[Int]("ID", O.PrimaryKey, O.AutoInc)
def name = column[String]("NAME")
def age = column[Int]("AGE")
def addressId = column[Int]("ADDRESS_ID")
def * = (id,name,age,addressId)
def address = foreignKey("ADDRESS",addressId,addresses)(_.id)
}
lazy val people = TableQuery[People]
...
type Address = (Int,String,String)
class Addresses(tag: Tag) extends Table[Address](tag, "ADDRESS") {
def id = column[Int]("ID", O.PrimaryKey, O.AutoInc)
def street = column[String]("STREET")
def city = column[String]("CITY")
def * = (id,street,city)
}
lazy val addresses = TableQuery[Addresses]
テーブルはケースクラスにマッピングされる。このコードは自動生成しても手で書いても良い。
Queries in comparison
JDBC Query
エラーハンドリングを伴うJDBCのクエリはこのように書ける。
import java.sql._
Class.forName("org.h2.Driver")
val conn = DriverManager.getConnection("jdbc:h2:mem:test1")
val people = new scala.collection.mutable.MutableList[(Int,String,Int)]()
try{
val stmt = conn.createStatement()
try{
val rs = stmt.executeQuery("select ID, NAME, AGE from PERSON")
try{
while(rs.next()){
people += ((rs.getInt(1), rs.getString(2), rs.getInt(3)))
}
}finally{
rs.close()
}
}finally{
stmt.close()
}
}finally{
conn.close()
}
Slickはクエリを記述するのに2つの方法を提供してくれている。1つはJDBCのようにSQL文字列をそのまま書くこと、もう1つの方法は型安全で合成可能なクエリを記述する事である。
Slick Plain SQL queries
もしSQLを用いてクエリを書き続けたい、もしくはSlickにまだサポートされていない機能が必要なら、SlickのPlain SQLクエリが役立つ。SlickのPlain SQLを用いて上記の例と同様のクエリを記述すると、以下のようになる。この中にはエラーハンドリングや、非同期実行のために最適化されたリソース管理機能などが含まれている。
import slick.driver.H2Driver.api._
...
val db = Database.forConfig("h2mem1")
...
val action = sql"select ID, NAME, AGE from PERSON".as[(Int,String,Int)]
db.run(action)
.listは結果のリストを返し、.headは結果を1つだけ貸す。.foreachは全ての結果を1度だけイテレートさせて取り扱うのに用いられる。
Slick type-safe, composable queries
Slickの重要な機能の1つとして、型安全で合成可能なクエリがある。SlickはScalaからSQLへ変換するためののコンパイラを持っている。基本的なライブラリのサブセットやいくつかの拡張についても利用可能である。Scala開発者はSQLについて知らなくても少しの基本的学習と特定の方言について覚えるだけで、関連データベースに対する多くのクエリを即座に記述する事が出来るようになる。Slickのクエリは合成可能である。これはSQL文字列を結合するかのような、joinに関する条件式であるとか、そのような繰り返し利用されるコードの重複を避けるための再利用可能な部分クエリを記述出来る事を表す。そのようなクエリは型安全であり、コンパイル時に間違いを発見出来るのみならず、SQLインジェクションのリスクをなくす事が出来る。
型安全なSlickによるクエリは、上記JDBCの例と同じサンプルに対して、以下のように記述出来る。
import slick.driver.H2Driver.api._
...
val db = Database.forConfig("h2mem1")
...
val query = people.map(p => (p.id,p.name,p.age))
db.run(query.result)
.runは自動的にコレクション風のクエリにはSeqを、スカラ値に対するクエリには単一の結果を返す。.list、.head、.foreachも同様に利用できる。
SQL文字列利用する場合と比較して、メソッド呼び出しによりクエリを簡単に組み立てる事が出来る。例として、query.filter(_.age > 18)は結果を絞り込むようなクエリを返す。これにより、メンテナンスしやすい、再利用可能なクエリを作成する事ができる。joinに対する条件や、ページング、絞り込みなど、様々な抽象化が行える。
Slickはクエリの型チェックを行うための型情報を必要とすることに注意して欲しい。このような型情報は、データベーススキーマと強く紐付いていなくてはならず、上の方で記述したように、TableのサブクラスとTableQueryの値を定義してあげる必要がある。
Main obstacle: Semantic API differences
ScalaのコレクションのメソッドがSQLに備わっているものと少し異なる事がある。新しくSQLの知識を基にSlickを学ぼうと考えている人にとっては、少し障壁となってしまう可能性がある。特にgroupByはトリッキーなものに思えるだろう。
Slickの型安全なAPIを利用したクエリを記述するための最適なアプローチとして、Scalaのコレクションについて考えてみるのが良い。もしSlickのTableQueryオブジェクトの代わりに、タプルやケースクラスのSeqを扱う場合には、コードはどのようなものになっているだろうか。恐らく同じようなコードを記述する事になるだろう。もしScalaのライブラリの特徴がSlickによってサポートされていなかったり、少し異なるものになっている場合には、別途一時的に対応する必要がある。いくつかの操作に関しては、Scalaの場合よりSlickの場合の方が強い型情報を持つ事がある。違いの1つとして、算術演算には.asColumnOf[T]を用いた明示的なキャストを必要とする。またSlickはOption操作のために3つの値のロジックを用いている (Also Slick uses 3-valued logic for Option inference.)。
Scala-to-SQL compilation during runtime
Slickは型安全なクエリを提供するために、ScalaからSQLへ変換するためのコンパイラを持っている。このコンパイラはScalaのランタイムに実行され、複雑なクエリに対しては少しばかりの時間を必要とする。クエリが定義される度に1度だけコンパイラが実行されるのは、非常に役立つ。実行時に毎度行われる代わりに、アプリ起動時にコンパイルさせるなど。Compiled queriesを用いると、再利用のために生成されたSQLをキャッシュさせる事が出来る。
Limitations
Slickを大々的に使っている場合にいくつかのケースで、Slickの型安全なクエリ言語がクエリオペレータやJDBCの機能を一部サポートしていないために、最適化されてないSQLコードを使いたいといった要求があるかもしれない。これに対処する方法がいくつかある。
Missing query operators
Slickに対して、存在していないオペレータを追加してあげる事が出来る。
Definition in terms of others
Slickに既に存在するオペレータを用いて、何かしらの拡張を行いたい場合には、単にScalaのメソッドを書くか、存在するオペレータに対してメソッドを生やすような暗黙的クラスを書くと良い。以下の例では、squaredというメソッドを追加している。
implicit class MyStringColumnExtensions(i: Rep[Int]){
def squared = i * i
}
...
// usage:
people.map(p => p.age.squared)
Definition using a database function
もしスカラ値を操作するような基本的オペレータが必要なら、それも実装して拡張してあげたら良い。例えばSlickにはpowerというメソッドが無いが、データベースの関数にあるPOWERを呼び出すには、以下のようなマッピングを定義する。
val power = SimpleFunction.binary[Int,Int,Int]("POWER")
...
// usage:
people.map(p => power(p.age,2))
この部分に関する詳細な情報が欲しければ、Scalar database functionsを参考にして欲しい。
データベースの関数を利用するクエリを操作するオペレータを追加することは出来ない。これは、SlickのScalaからSQLへ変換するコンパイラが最もシンプルなSQLクエリへコンパイルしようとする際、クエリの構造についての知識を必要とするためである。ゆえに、今現在ではカスタムクエリオペレータを取り扱う事は出来ない(この制限をどうにかしようとするアイデアはいくつかあるが、もう少し調査が必要である)。そのようなオペレータの例として、MySQLのindexヒントなどがある。これはSlickの型安全なAPIではサポートすることができず、ユーザによって追加することも出来ない。もしそのようなオペレータを操作する必要がある場合には、SlickのPlain SQLを使ってクエリを書いて欲しい。もしそのオペレータの返り値が変わらないものである場合には、次章で説明する一時的な解決法を利用することが出来るかもしれない。
Non-optimal SQL code
SlickはSQLを生成する際、出来る限りシンプルなクエリを作成しようとする。このアルゴリズムは完璧なものにはなっておらず、目下良いものにしようと開発中である。生成されたクエリが、手で記述したものよりもより複雑なものになってしまうケースもある。オプティマイザやDBMSを通してもこのようなクエリは悪いパフォーマンスとなる場合もある。例えばSlickは時折不必要なサブクエリを生成する。MySQLの5.5以下の場合において、不必要なテーブルスキャンと利用されないインデックスを用いることがある。Slickの開発チームはクエリオプティマイザが最適化出来るようなより良いコードを生成できるように取り組んでいる。このような場合の対処法としては、最適なSQLコードを手で書いてしまうしかない。手で書いたものはSlickのPlain SQLを通して実行できるし、このようなハックを利用するのも良い。この例では、型安全なクエリの対してSQLのコードを取って替えてしまっている。
people.map(p => (p.id,p.name,p.age))
.result
// 手で書いたSQLを注入している (https://gist.github.com/cvogt/d9049c63fc395654c4b4)
.overrideSql("SELECT id, name, age FROM Person")
SQL vs. Slick examples
本節では、利用頻度の多いSQLクエリと同じ意味をなすSlickの型安全なクエリとを比較して順に見ていく。
SELECT *
SQL
sql"select * from PERSON".as[Person]
Slick
SlickでSELECT *という記述は、TableQueryのresultを指す。
people.result
SELECT
SQL
sql"""
select AGE, concat(concat(concat(NAME,' ('),ID),')')
from PERSON
""".as[(Int,String)]
Slick
SELECTによる射影は、Scalaのmapに相当する。カラムは同様のものを指せば良いし、カラムに対する関数操作はScalaにおける同様のオペレータを基本的にはそのまま用いる事ができる(ただし、文字列の結合には+ではなく++を用いる)。
people.map(p => (p.age, p.name ++ " (" ++ p.id.asColumnOf[String] ++ ")")).result
WHERE
SQL
sql"select * from PERSON where AGE >= 18 AND NAME = 'C. Vogt'".as[Person]
Slick
WHERE条件は、Scalaのfilterを用いれば良い。==は利用できず、===を代わりに用いなければならない。
people.filter(p => p.age >= 18 && p.name === "C. Vogt").result
ORDER BY
SQL
sql"select * from PERSON order by AGE asc, NAME".as[Person]
Slick
ORDER BYはScalaのsortByを利用する。複数カラムを用いたソートにはタプルを渡してあげる必要がある。Slickの.ascと.descメソッドも昇順・降順を選ぶのに利用出来る。複数回.sortBy呼び出しを行うのは、複数カラムに対してORDER BYのと同じ挙動にはならない。複数カラムを用いたORDER BYには、.sortByに1度だけタプルを渡して欲しい。
people.sortBy(p => (p.age.asc, p.name)).result
Aggregations (max, etc.)
SQL
sql"select max(AGE) from PERSON".as[Option[Int]].head
Slick
集約関数については、Scalaにもある同じようなコレクションの操作関数を用いる事ができる。SQLではカラムに対して集約関数を呼び出すが、Slickではコレクションに対し集約メソッドを呼び出す。結果は個々に実行され、スカラー値が返却される。maxのような集約関数はNULLが返る事があるため、SlickではOptionが返却される。
people.map(_.age).max.result
GROUP BY
SQLを利用していた人にとって理解しにくいものの1つが、SlickのgroupByである。なぜなら、これはSQLとSlickで異なるシグニチャになるためである。SQLのGROUP BYはグルーピングを行うkeyで、グループ内の全ての要素をもとにした集合を生成する操作を行うような挙動になる。SQLではグルーピングされたコレクションから1つの値を取得するための、avgのような集約関数を実行する事が必要になる。
SQL
sql"""
select ADDRESS_ID, AVG(AGE)
from PERSON
group by ADDRESS_ID
""".as[(Int,Option[Int])]
Slick
ScalaのgroupByでは、グルーピングを行うkeyをもとに、各グループを列のListを値とするMapを作成する。各々のカラムをコレクションに自動的に変換したりはしない。SQLで集約を行うような操作をするには、得られたグループから必要なカラムへマッピングする操作行うといったように、Scala側で操作を明示的に行わなくてはならない。
people.groupBy(p => p.addressId)
.map{ case (addressId, group) => (addressId, group.map(_.age).avg) }
.result
SQLではグループ化された値を集約させる必要がある。そのため、Slickでも同じことを明示的に行わなくてはならない。これはつまり、groupByを呼び出した際には、その後にmapを呼び出すか、もし呼び出さない場合には例外を吐いて失敗してしまう。Slickのグループ化のシンタックスはSQLのものより少しばかり複雑なのだ。
HAVING
SQL
sql"""
select ADDRESS_ID
from PERSON
group by ADDRESS_ID
having avg(AGE) > 50
""".as[Int]
Slick
SlickはWHEREとHAVINGに対して異なるメソッドを持っていない。HAVINGを実現するためには、ただgroupByの後にfilterを行えば良い(さらにその後にmapも必要)。
people.groupBy(p => p.addressId)
.map{ case (addressId, group) => (addressId, group.map(_.age).avg) }
.filter{ case (addressId, avgAge) => avgAge > 50 }
.map(_._1)
.result
Implicit inner joins
SQL
sql"""
select P.NAME, A.CITY
from PERSON P, ADDRESS A
where P.ADDRESS_ID = a.id
""".as[(String,String)]
Slick
SlickはflatMapとmap(つまりfor式)によって暗黙的joinを生成する。
people.flatMap(p =>
addresses.filter(a => p.addressId === a.id)
.map(a => (p.name, a.city))
).result
...
// for式で同じ記述をすると、以下のようになる
(for(p <- people;
a <- addresses if p.addressId === a.id
) yield (p.name, a.city)
).result
Explicit inner joins
SQL
sql"""
select P.NAME, A.CITY
from PERSON P
join ADDRESS A on P.ADDRESS_ID = a.id
""".as[(String,String)]
Slick
Slickで明示的joinを生成するには、以下のようなDSLで書ける。
(people join addresses on (_.addressId === _.id))
.map{ case (p, a) => (p.name, a.city) }.result
Outer joins (left/right/full)
SQL
sql"""
select P.NAME,A.CITY
from ADDRESS A
left join PERSON P on P.ADDRESS_ID = a.id
""".as[(Option[String],String)]
Slick
outer joinはSlickの明示的なjoin DSLを使って書ける。注意して欲しいのはouter joinのSQLを用いると、結合時にnullにならないカラムがnullになり得る事だ。これに対しSlickでは、結合時にはそのようなカラムはOptionを返すようにしている。これに関して、結合時にマッチしなかった列と、元々NULLが含まれていてマッチした列との区別をすることが出来るようになっており、SQL本来の機能より良いものになっている。
(addresses joinLeft people on (_.id === _.addressId))
.map{ case (a, p) => (p.map(_.name), a.city) }.result
Subquery
SQL
sql"""
select *
from PERSON P
where P.ID in (select ID
from ADDRESS
where CITY = 'New York City')
""".as[Person]
Slick
Slickのクエリが合成可能である。サブクエリは単に予め用意されたクエリを用いるだけで済む。
val address_ids = addresses.filter(_.city === "New York City").map(_.id)
people.filter(_.id in address_ids).result // <- run as one query
.inにはサブクエリを渡す。インメモリのScalaコレクションに対しては.inSetを用いる。
Scalar value subquery / custom function
SQL
sql"""
select * from PERSON P,
(select rand() * MAX(ID) as ID from PERSON) RAND_ID
where P.ID >= RAND_ID.ID
order by P.ID asc
limit 1
""".as[Person].head
Slick
このコードではuser-defined database functionで説明した、単一の値を計算して返す関数を用いたサブクエリの使い方を示している。
val rand = SimpleFunction.nullary[Double]("RAND")
...
val rndId = (people.map(_.id).max.asColumnOf[Double] * rand).asColumnOf[Int]
...
people.filter(_.id >= rndId)
.sortBy(_.id)
.result.head
insert
SQL
sqlu"""
insert into PERSON (NAME, AGE, ADDRESS_ID) values ('M Odersky', 12345, 1)
"""
Slick
SQLを学んでいた人から見ると、挿入操作は初めに驚くべきポイントの1つになると思う。なぜなら、SQLと違ってSlickでは挿入すべきカラムを選択したクエリを再利用させる事が出来るからである。基本的には初めに選択用のクエリを書き、挿入を実行するActionとして+=を呼び出す。一度に複数の列を挿入する際には、++=にSeqを渡す。auto incrementなカラムは自動的に無視される。forceInsertを用いると、auto incrementされたカラムへ直接値を挿入することが出来る。
people.map(p => (p.name, p.age, p.addressId)) += ("M Odersky",12345,1)
update
SQL
sqlu"""
update PERSON set NAME='M. Odersky', AGE=54321 where NAME='M Odersky'
"""
Slick
挿入時と同じように、更新操作も更新を行いたいデータをfilterなどを用いて選択した後に、.updateにより値を更新させる。
people.filter(_.name === "M Odersky")
.map(p => (p.name,p.age))
.update(("M. Odersky",54321))
delete
SQL
sqlu"""
delete PERSON where NAME='M. Odersky'
"""
Slick
こちらも挿入時と同じように、削除したいデータを選択した後に削除を行う。クエリの結果を得るためではなく、.deleteは選択された列を削除するActionを得るために用いられる。
people.filter(p => p.name === "M. Odersky")
.delete
CASE
SQL
sql"""
select
case
when ADDRESS_ID = 1 then 'A'
when ADDRESS_ID = 2 then 'B'
end
from PERSON P
""".as[Option[String]]
Slick
SlickではCASEのための、小さなDSLを用意している。
people.map(p =>
Case
If(p.addressId === 1) Then "A"
If(p.addressId === 2) Then "B"
).result
Slick 3.0.0 documentation - 13 Upgrade Guides
Permalink to Upgrade Guides — Slick 3.0.0 documentation
アップグレードガイド
Compatibility Policy
SlickはScalaの2.10か2.11のバージョンで動作する(Scala 2.9を使ってる人は、Slickの前身であるScalaQueryを使って欲しい)。
Slickのバージョンナンバーはepoch、メジャーバージョン、マイナーバージョン、RCやSNAPSHOTといった修飾子からなる。
Slickのリリースバージョン(修飾子のついてないもの)においては、同じepochとメジャーバージョンの付くものに対し、バイナリ互換性が保証されている(2.1.2に対して、2.1.0と互換性があるが、2.0.0とは互換性の保証が無い)。Slick Extensionsは少なくともSlickの同じマイナーバージョンが必要とされる(e.g. Slick Extension 2.1.2にはSlick 2.1.2を用いて、Slick 2.1.1は用いてはならない)。slick-codegen はコンパイル時に用いられる事を期待しているため、互換性は保持されていない。
ソースコードに対する互換性は保証していないものの、同じメジャーリリースに対しては出来る限り保証しようと試みてはいる。新しいメジャーリリースにアップグレードしようとする際には、いくつかあなた側のソースを変更する必要が出てくるだろう。古い機能については非推奨にし、メジャーリリースのサイクルに対してはそのままのコードが使えるようにはしている。例として、2.1.0で非推奨になった機能は2.2.0で削除される。ただし、全ての変更に対して同じようにならない事もあるので注意して欲しい。
RC (Release candidates) は出そうと試みているバージョンと互換性が保証されるようになっている。milestonesやsnapshotは、互換性が保証されていない。
Upgrade from 2.1 to 3.0
Package Structure
Slickはパッケージ名をscala.slickからslickへと変更された。共通の型や値が含まれていたscala.slickのパッケージオブジェクトには、非推奨なエイリアスが残されている。
Database I/O Actions
ドライバからsimpleやImplicitsをインポートするのは非推奨となり、Slick 3.1で機能が削除される。その代わりに同様の機能を提供するapiを使って欲しい(ただしデータベース呼び出しをブロッキングしてしまうInvokerやExecutorというAPIは含まれていない)。ここに含まれていた機能は、新しいAPIであるモナディックデータベースI/Oアクションに取って替えられている。このAPIについての詳細はDatabase I/O Actionsを見て欲しい。
Join Operators
以前のouter joinオペレータはnullを含む場合に、ユーザコード内で複雑にマッピングを行う必要もあったり、正しく処理していなかった。特にネストされたouter joinを用いていたり、マッピングされたエンティティを用いたouter joinを行っていた場合に、正確な処理が行えていなかった。新しいouter joinオペレータでは、left joinやright join、full outer joinの結合時に、Optionに結果を持ち上げる事で複雑なマッピング等を行う必要がなくなった。ネストされたOptionやSlickでプリミティブ型以外に対するOptionをサポートすることにより、この機能を実現する事ができた。。
古いjoinに対応するオペレータはまだ利用可能ではあるが、非推奨となった。非推奨APIに対する警告に従い、適宜以下のように変更して欲しい。
- leftJoin -> joinLeft
- rightJoin -> joinRight
- outerJoin -> joinFull
- innerJoin -> join
新しいjoinセマンティックにおいては、joinオペレータにJoinTypeを明示的に渡しても何の意味もなさないし、その方法は非推奨になっている。今現在、joinはinner joinのためにのみ用いられる。
first
昔のInvoker APIでは、firstやfirstOptionはクエリの結果に対するコレクションの先頭の値を取得するのに使われていた。新しいAPIにおいては、同様のオペレーションはheadとheadOptionを呼び出す事で提供される。これはScalaのコレクションAPIで用いられているものとの調和を図るためである。
Column Type
Column[T]という型はRep[T]のサブタイプへ包含された。個々のカラムのためにのみ利用可能であったオペレーションには、暗黙的なTypedType[T]が要求される。暗黙的なShapeを作成する際に、Optionカラムをより柔軟に扱うために、OptionとOptionでないカラムの双方を要求する。つまりこのケースにおいては、OptionTypedType[T]かBaseTypedType[T]が必要になる。もし双方を抽象化したいのなら、暗黙的パラメータとして要求されているShapeを渡し、具象型が分かる前提でそいつが呼び出し側でインスタンス化されるようにしておくと、より便利に扱えるようになる。
Column[T]は依然、Rep[T]のためのエイリアスとして非推奨ながら利用出来る。暗黙的な値が必要とされることがあるため、全ての場合において利用できるような完璧な後方互換になっているわけではない。
Closing Databases
今やDatabaseインスタンスは関連のあるコネクションプールやスレッドプールを持っているため、それらを使い終わった際には適切にスレッドプールなどをシャットダウンするために、shutdownやcloseを呼んで欲しい。新しいアクションベースなAPIへ移行する際には、この点に気をつけてほしい。非推奨な同期APIを用いている場合に限り、この処理は厳格には必要無い。
Warning
遅延初期化に頼らないで!!Slick 3.1ではcloseする際、常に
Databaseオブジェクトが必要になる。さらに、Slick 3.1ではコネクションやスレッドプールが即座に作られるかもしれない。
Metadata API and Code Generator
slick.jdbc.metaパッケージにあるJDBCメタデータAPIは、InvokerではなくActionを作成する新しいAPIに変更された。このAPIを利用しているコードジェネレータも非同期APIを利用するように完全に書き換えられた。同じ機能とコンセプトはまだサポートされてはいるものの、コードジェネレータのカスタマイズ部分にはいくつか変更を加えなくてはならないだろう。コードジェネレータのテストとSchema Code Generationの例を読んで欲しい。
Inserting from Queries and Expressions
Slick 2.0から、auto incrementなカラムを無視するような挿入処理が挿入時のデフォルトの挙動となっている。他のクエリや計算された結果を用いて挿入をしたい時には、force-insertセマンティックを用いる事が出来る(auto incrementなカラムに対しても値を挿入したい時など)。新しいDBIO APIはinsert(Query)をforceInsertQuery(Query)に、insertExprをforceInsertExprに変更することで、このような処理を実現している。
Default String Types
JdbcProfile内に制約の無いString型のカラムは、デフォルトでVARCHAR(254)として扱われていた。既にH2DriverのようないくつかのドライバではString型のカラムに対して、制約のない型が割り当てられるよう変更されている。Slick 3.0では、PostgreSQLにおいてはVARCHARが、MySQLにおいてはTEXTが用いられている。以前は無害なものであったものの、MySQLのTEXTはGLOBとよく似た型になっており、いくつかの制約がかかる(デフォルト値を持たなかったり、長さの制約を与えないとインデックスが効かなかったり)。明示的にO.Length(254)のようなカラムのオプションを用いる事で、以前の挙動に戻す事ができるし、application.confにあるslick.driver.MySQL.defaultStringTypeというキーでデフォルト値を変更することも出来る。
JdbcDriver
JdbcDriverオブジェクトは非推奨となった。使用しているデータベースに対応する正しいドライバを用いて欲しい。
Upgrade from 2.0 to 2.1
Query type parameters
Queryは以前は2つの型引数を取っていたが、今は3つの型引数を取る。以前のQuery[T,E]はSlick 2.1におけるQuery[T,E,Seq]と等しい。3つ目の型引数は.runをクエリに対し実行した際の返り値となるべきコレクション型だ(Sli 2.0では常にSeqが返されていた)。将来的にはクエリをScalaのコレクション型の対応するものと同じ挙動を示すように変更する予定だ。例として、Query[_,_,Set]は要素のユニーク性を持っていたり、Query[_,_,List]には順序があるなど。コレクションの型は.to[C]をクエリに対し呼び出すことでCへ変更させる事が出来る。
Slick 2.1へアップグレードするには、次のいずれかの処理を行う必要がある。1つ目の方法としては、新しいQueryの型を違う名前の 何か に置き換えることだ。これはつまり、importを、import ....simple.{Query=>NewQuery,_}と記述し、それからtype Query[T,E] = NewQuery[T,E,Seq]というエイリアスを用意することに対応する。2つ目の方法としては、SeqをQueryの第三型引数に追加する事だ。次の正規表現を用いると簡単に変換出来るかもしれない。変換前: ([^a-zA-Z])Query\[([^\]]+), ?([^\]]+)\]、変換後: \1Query[\2, \3, Seq]。
.list and .first
これらのメソッドは、Slick 2.0において暗黙的な引数リストの前に空の引数を渡していた。統一性のために、これらの引数は渡さなくて良くなった。.list()という呼び出しは.listで、.first()は.firstと呼び出して欲しい。
.where
このメソッドはScalaのコレクションには存在しないため、非推奨となった。代わりに.filterを使って欲しい。
.isNull and .isNotNull
同様に、これらのメソッドはScalaのスタンダードライブラリには無いため非推奨となった。代わりにisEmptyとisDefinedを仕様して欲しい。今やこれらのメソッドはOptionのカラムにおいてのみ利用されている。Optionで無いカラムに対してこれらのメソッドを使うには、.?を用いてOptionなカラムになるようキャストすれば良い(e.g. someCol.?.isDefined)。これを行わなければならないのは、カラムに対して誤った型付を行っているためであり、nullになりえてOptionで無いカラムについては、Table定義を修正すべきである。
Static Plain SQL Queries
プレースホルダ構文に対するインターフェースに変更が加えられた。Slick 2.0では以下のようにかけていた。
StaticQuery.query[T,…]("select ...").list(someT)
これは、Slick 2.1では以下のように記述しなくてはならない。
StaticQuery.query[T,…]("select ...").apply(someT).list
Slick code generator / Slick model
コードジェネレータはSlick本体の開発を促進するために、異なるアーティファクトへと移動された。以前はslick.model.codegenというパッケージ名を利用していたが、今はslick.codegenに置かれている。バイナリ互換性は、コードジェネレータがコンパイル毎に利用されることを期待して、保証されていない。sbtプロジェクトでコードジェネレータを利用する際は、以下のdependencyを追加して欲しい。
"com.typesafe.slick" %% "slick-codegen" % "3.0.0"
SourceCodeGenerator#Table#compoundは、複合値の値と型双方に対して整形された異なるコードを生成する、compoundValueとcompoundTypeという2つのメソッドに分離された。
デフォルトとなるデータベースの全てのテーブルのリストを得るためのInvokerを返すSlickドライバのgetTablesというメソッドは、非推奨となった。代わりとなるものは、現時点で存在するメタテーブルをSlickに取り除かせるために、直接テーブル一覧を返すdefaultTablesというメソッドになる。
slick.jdbc.meta.createModel(tables)というメソッドはドライバの中へ移動し、H2Driver.createModel(Some(tables))のような記述で実行される。
Slickによって生成されたモデルはMySQLに対し、データベースのカラム型、文字列カラムの文字数、文字列のデフォルト値のような様々な情報を含んでいる。コードジェネレータは可搬的な長さのような情報を生成されたコードに埋め込み、可搬的でないデータベースのカラム型のような情報を生成されたコードに埋め込む事はオプショナルな機能とした。もしそのような設定にするのなら、SlickCodeGenerator#Table#Column#dbTypeをtrueにして欲しい。
jdbcのメタデータからモデルの生成をカスタマイズするために、どのようにしてコードジェネレータがカスタマイズされるのかという点において、新しいModelBuilderは拡張されている。Slickにおいてモデルを生成したり失われた特徴を組み直す際、これはjdbcドライバ間の違いやバグを上手いことフォローアップしている(dbmsにある特殊な型をサポートするなど)。
Upgrade from 1.0 to 2.0
Slick2.0はSlick1.0に互換性のない拡張が含まれている。アプリケーションを1.0から2.0へ移行する際には、以下のような変更が必要になるだろう。
Code Generation
以前は手で書いていたテーブルへのマッピングを、2.0ではデータベーススキーマを用いて自動的に生成出来るようになった。code-generaterは柔軟にカスタマイズすることも出来るため、より最適化されたものに変更する事も出来る。詳細については、More info on code generationを参考にして欲しい。
Table Descriptions
Slick1.0では、テーブルはvalやtable objectと呼ばれるobjectによって定義がなされ、射影*では~オペレータを用いてタプルを表していた。
// --------------------- Slick 1.0 code -- does not compile in 2.0 ---------------------
object Suppliers extends Table[(Int, String, String)]("SUPPLIERS") {
def id = column[Int]("SUP_ID", O.PrimaryKey)
def name = column[String]("SUP_NAME")
def street = column[String]("STREET")
def * = id ~ name ~ street
}
Slick2.0ではTagを引数にテーブルクラスの定義を行い、実際のデータベーステーブルを表すTableQueryのインスタンスを定義する。射影*に対し、基本的なタプルを用いて定義を行うことも出来る。
class Suppliers(tag: Tag) extends Table[(Int, String, String)](tag, "SUPPLIERS") {
def id = column[Int]("SUP_ID", O.PrimaryKey)
def name = column[String]("SUP_NAME")
def street = column[String]("STREET")
def * = (id, name, street)
}
val suppliers = TableQuery[Suppliers]
以前に用いていた~シンタックスをそのまま使いたい場合には、TupleMethod._をインポートすれば良い。TableQuery[T]を用いると、内部的にはnew TableQuery(new T(_))のような処理が行われ、適切なTableQueryインスタンスが作成される。Slick1.0では共通処理に関して、静的メソッドでテーブルオブジェクトに定義がなされていた。2.0においても以下のようにカスタムされたTableQueryオブジェクトを用いて、同様の事が出来る。
object suppliers extends TableQuery(new Suppliers(_)) {
// put extra methods here, e.g.:
val findByID = this.findBy(_.id)
}
TableQueryはデータベーステーブルのためのQueryオブジェクトのことである。予期せぬ場所で適用されるQueryへの暗黙的な変換はもはや必要無い。Slick 1.0において生身の table object を扱っていた場所は、全て table query が代わりに用いられることになる。例として、以下に挙げられる挿入(inserting)や、外部キー関連などがある。
Mapped Tables
- 0において双方向マッピングを行っていた
<>関数はオーバーロードされ、今やケースクラスのapply関数を直接渡す事が出来る。
// --------------------- Slick 1.0 code -- does not compile in 2.0 ---------------------
def * = id ~ name ~ street <> (Supplier _, Supplier.unapply)
上記のような記述はもはや3.0ではサポートされていない。その理由の1つとして、このようなオーバーロードはエラーメッセージを複雑にしすぎるためである。現在では適切なタプル型を用いて関数を定義する事が出来る。もしケースクラスをマッピングしたいのならば、コンパニオンオブジェクトの.tupledを単純に用いれば良いのである。
def * = (id, name, street) <> (Supplier.tupled, Supplier.unapply)
case class Supplier(id: Int, name: String, street: String)
object Supplier // overriding the default companion object
extends ((Int, String, String) => Supplier) { // manually extending the correct function type
//...
}
def * = (id, name, street) <> ((Supplier.apply _).tupled, Supplier.unapply)
Profile Hierarchy
Slick 1.0ではBasicProfileとExtendedProfileの2つのプロファイルを提供していた。Slick 2.0ではこれら2つのプロファイルをJdbcProfileとして統合している。今ではRelationalProfileに挙げられるようなより抽象的なプロファイルを提供している。RelationalProfileはJdbcProfileの全ての特徴を持っているわけではないが、新しく出来たHeapDriverやDistributedDriberといった機能を支えている。Slick 1.0からコードを移植する際、JdbcProfileへとプロファイルを変更して欲しい。特にSlick 2.0におけるBasicProfileは1.0におけるBasicProfilと非常に異なったものになっているので注意して欲しい。
Inserting
Slick1.0では挿入時にtable objectの一部を射影していた。
// --------------------- Slick 1.0 code -- does not compile in 2.0 ---------------------
(Suppliers.name ~ Suppliers.street) insert ("foo", "bar")
- 0においてtable objectは存在していないため、table queryから射影しなくてはならない。
suppliers.map(s => (s.name, s.street)) += ("foo", "bar")
+=オペレータはScalaコレクションとの互換性のために用いられており、insertという古い名前の関数はエイリアスとして依然用いる事が出来る。
Slick 2.0ではデータを挿入する際自動的にデフォルトでAutoIncのついたカラムを除外する。1.0では、そのようなカラムについて手動で除外した射影関数を別に用意しなくてはならなかった。
// --------------------- Slick 1.0 code -- does not compile in 2.0 ---------------------
case class Supplier(id: Int, name: String, street: String)
object Suppliers extends Table[Supplier]("SUPPLIERS") {
def id = column[Int]("SUP_ID", O.PrimaryKey, O.AutoInc)
def name = column[String]("SUP_NAME")
def street = column[String]("STREET")
// Map a Supplier case class:
def * = id ~ name ~ street <> (Supplier.tupled, Supplier.unapply)
// Special mapping without the 'id' field:
def forInsert = name ~ street <> (
{ case (name, street) => Supplier(-1, name, street) },
{ sup => (sup.name, sup.street) }
)
}
Suppliers.forInsert.insert(mySupplier)
- 0においてこのような冗長な記述は必要無くなる。デフォルトの射影関数を挿入時に用いる事で、自動インクリメントのついた
idというカラムをSlickが除外してくれる。
case class Supplier(id: Int, name: String, street: String)
class Suppliers(tag: Tag) extends Table[Supplier](tag, "SUPPLIERS") {
def id = column[Int]("SUP_ID", O.PrimaryKey, O.AutoInc)
def name = column[String]("SUP_NAME")
def street = column[String]("STREET")
def * = (id, name, street) <> (Supplier.tupled, Supplier.unapply)
}
val suppliers = TableQuery[Suppliers]
suppliers += mySupplier
逆にAutoIncのついたカラムに対し値を挿入したいのならば、新しく出来たforceInsertやforceInsertAllといった関数を用いれば良い。
Pre-compiled Updates
Slickはselect文において用いられるのと同じ方法で、update文における事前コンパイルもサポートしている。これについては、Compiled Queriesのセクションを見て欲しい。
Database and Session Handling
Slick 1.0ではDatabaseのファクトリオブジェクトとして標準的なJDBCベースなDatabaseとSessionといった型がscala.slick.sessionパッケージにある。Slick 2.0からはJDBCベースなデータベースに制限せず、このパッケージは(backendとしても知られる)DatabaseComponent階層
によって置き換えられている。もしJdbcProfile抽象レベルで動かしたいのならば、以前にscala.slick.sessionにあったものをインポートし、常にJdbcBackendを用いれば良い。ただし、simple._といったインポートを行うと自動的にスコープ内にこれらの型が持ち込まれてしまうので注意して欲しい。
Dynamically and Statically Scoped Sessions
Slick 2.0では依然としてスレッドローカルな動的セッションと静的スコープセッションを提供している。しかしシンタックスが変わっており、静的スコープセッションを用いる際にはより簡潔な記述が推奨される。以前のthreadLocalSessionはdynamicSessionという名前に変わっており、関連するwithSessionやwithTransactionといった関数もwithDynSessionとwithDynTransactionという名前にそれぞれ変わっている。Slick 1.0では以下のようなシンタックスで記述をしていた。
// --------------------- Slick 1.0 code -- does not compile in 2.0 ---------------------
import scala.slick.session.Database.threadLocalSession
myDB withSession {
// use the implicit threadLocalSession here
}
Slick 2.0で以下のようなシンタックスへ変わる。
import slick.jdbc.JdbcBackend.Database.dynamicSession
myDB withDynSession {
// use the implicit dynamicSession here
}
Slick 1.0では静的スコープセッションにおける明示的な型宣言が必要だった。
myDB withSession { implicit session: Session =>
// use the implicit session here
}
これは2.0において必要なくなる。
myDB withSession { implicit session =>
// use the implicit session here
}
また、動的セッションを使うことは確かな情報を取得できるか分からない事から推奨されていない。静的セッションを用いる方がより安全である。
Mapped Column Types
Slick 1.0のMappedTypeMapperはMappedColumnTypeへと名前が変わった。MappedColumnType.baseを用いるような基本的な操作はRelationalProfileレベル(高度な利用法をするのならば依然としてJdbcProfileが必要)において現在も利用できる。
// --------------------- Slick 1.0 code -- does not compile in 2.0 ---------------------
case class MyID(value: Int)
implicit val myIDTypeMapper =
MappedTypeMapper.base[MyID, Int](_.value, new MyID(_))
この記述は、以下のように変わる。
case class MyID(value: Int)
implicit val myIDColumnType =
MappedColumnType.base[MyID, Int](_.value, new MyID(_))
もしこの例のように単純なラッパー型へマッピングするのなら、MappedToを用いてもっと簡単に書くことが出来る。
case class MyID(value: Int) extends MappedTo[Int]
// No extra implicit required any more
Slick 3.0.0 documentation - 14 Slick Extensions
Permalink to Slick Extensions — Slick 3.0.0 documentation
Slick Extensionsについて
Typesafeにより提供された商用サポートを伴うクローズドなソースパッケージであるSlick Extensionsは、以下のデータベースのためのSlickドライバを含んでいる。
- Oracle (
com.typesafe.slick.driver.oracle.OracleDriver) - IBM DB2 (
com.typesafe.slick.driver.db2.DB2Driver) - Microsoft SQL Server (
com.typesafe.slick.driver.ms.SQLServerDriver)
Note
開発とテストを目的とした利用の際には、Typesafe Subscription Agreement (PDF) を読んだ上で利用して欲しい。プロダクション環境での利用をするには、Typesafe Subscriptionを見て欲しい。
もしsbtを利用しているのなら、Typesafeリポジトリにある slick-extensions を依存に加える事で利用出来る。
libraryDependencies += "com.typesafe.slick" %% "slick-extensions" % "3.0.0"
resolvers += "Typesafe Releases" at "<http://repo.typesafe.com/typesafe/maven-releases/>"
Slick 3.0.0 documentation - 15 Direct Embedding (Deprecated)
Permalink to Direct Embedding (Deprecated) — Slick 3.0.0 documentation
Direct Embedding(非推奨)
バージョン3.0から非推奨となるAPI
DirectEmbeddingはSlick1.0の頃に加えられた、実験的なクエリAPIであったが、バージョン3.0より非推奨となった。この機能はバージョン3.1に削除される予定だ。プロダクション環境などでは、Slickの標準的なクエリAPIを利用して欲しい。
Unlike the standard API, the direct embedding uses macros instead of operator overloading and implicit conversions for its implementation. For a user the difference in the code is small, but queries using the direct embedding work with ordinary Scala types, which can make error messages easier to understand.
Dependencies
direct embeddingは型検査のために実行時にScalaコンパイラにアクセスする必要がある。Slickは必要性に駆られない限り、アプリケーションに対し、依存性を避けるためにScalaコンパイラへの依存性を任意としている。そのため、direct embeddingを用いる際にはプロジェクトの build.sbt に対し明示的にその依存性を記述しなくてはならない。
libraryDependencies <+= (scalaVersion)("org.scala-lang" % "scala-compiler" % _)
Imports
import slick.driver.H2Driver
import H2Driver.api.{Database, DBIO}
import slick.direct._
import slick.direct.AnnotationMapper._
Row class and schema
スキーマは現在でえは行を保持しているケースクラスに対してアノテーションを付与する事で記述する事が出来る。今後、より柔軟にスキーマの情報を拡張出来るような機能を提供する予定だ。
// describe schema for direct embedding
@table(name="COFFEES")
case class Coffee(
@column(name="NAME")
name : String,
@column(name="PRICE")
price : Double
)
Query
Queryableはテーブルデータに対しクエリの演算を行うためのものであり、注釈付けられた型引数を取る。
_.price はここではInt型である。潜在的な、マクロベースの実装においてはmapやfilterに与えられた引数はJVM上で実行されないが、その代わりにデータベースクエリへと変換される事を覚えておいて欲しい。
// query database using direct embedding
val q1 = Queryable[Coffee]
val q2 = q1.filter( _.price > 3.0 ).map( _ .name )
Execution
クエリを実行するためには、選択したデータベースのドライバを用いるSlickBackendインスタンスを作成する必要がある。
val db = Database.forConfig("h2mem1")
try {
// execute query using a chosen db backend
val backend = new SlickBackend( H2Driver, AnnotationMapper )
println( Await.result(db.run(backend.result(q2)), Duration.Inf) )
println( Await.result(db.run(backend.result(q2.length)), Duration.Inf) )
} finally db.close
Alternative direct embedding bound to a driver and session
ImplicitQueryableを用いると、queryableはバックエンドとセッションに束縛される。クエリはその上で以下のような方法で簡単に実行する事が出来る。
//
val iq1 = ImplicitQueryable( q1, backend, db )
val iq2 = iq1.filter( c => c.price > 3.0 )
println( iq2.toSeq ) // <- triggers execution
println( iq2.length ) // <- triggers execution
Features
direct embeddingは現在、 String, Int, Double といった値に対しマッピングされるデータベースカラムのみをサポートしている。
QueryableとImplicitQueryableは現在、次のようなメソッドを用意している。
map, flatMap, filter, length
これらのメソッドはimmutableな演算を行うが、関数呼び出しによる変化を包含した新しいQuaryableを返す。
上記の関数におけるシンタックスとして、以下のオペレータを利用する事が出来る。
Any: ==
Int, Double: + < >
String: +
Boolean: || &&
他に定義された独自のオペレータについても、型検査がマッチしていれば利用する事が出来る。しかし現時点では、それらのオペレータは実行時に失敗するクエリを生成するようなSQLへ変換する事が出来ない。(例: ( coffees.map( c => c.name.repr ) ))将来的には、コンパイル中にそのようなものもキャッチするような方法を検討している。
クエリは行を補完するようなオブジェクトを保持する、任意にネストされたタプルのシーケンスを結果として返す。
q1.map( c => (c.name, (c, c.price)) )
Slick 3.0.0 documentation - 16 Slick TestKit
Permalink to Slick TestKit — Slick 3.0.0 documentation
Slick TestKitについて
Slickに対し、独自のデータベースドライバを記述する際には、きちんと動作するのか、何が現時点で実装されていないのかなどを確認するために、ユニットテスト(もしくは加えて他の独自のカスタマイズしたテスト)をきちんと記述して欲しい。簡単にテストを記述するためのサポートとして、Slickユニットテスト用のSlick Test Kitプロジェクトを別に用意している。
これを用いるためには、Slickの基本的なPostgreSQLドライバと、ビルドするために必要なものを全て含んだSlick TestKit Exampleをcloneして使って欲しい。
Scaffolding
build.sbtは以下のように記述する。一般的な名前とバージョン設定と区別して、SlickとTestKit、junit-interface、Logback、PostgreSQL JDBC Driverへの依存性を追加する。そしてテストを行うためのオプションをいくつか記述する必要がある。
libraryDependencies ++= Seq(
"com.typesafe.slick" %% "slick" % "|release|",
"com.typesafe.slick" %% "slick-testkit" % "|release|" % "test",
"com.novocode" % "junit-interface" % "0.10" % "test",
"ch.qos.logback" % "logback-classic" % "0.9.28" % "test",
"postgresql" % "postgresql" % "9.1-901.jdbc4" % "test"
)
...
testOptions += Tests.Argument(TestFrameworks.JUnit, "-q", "-v", "-s",
"-a")
...
parallelExecution in Test := false
...
logBuffered := false
src/test/resources/logback-test.xmlに、Slickのlogbackについての設定のコピーがある。もちろん、loggingフレームワーク以外のものを使う事も出来る。
Driver
ドライバの実装はsrc/main/scalaの中にある。
Test Harness
TestKitテストを実行するためには、DriberTestを継承したクラスを作成する必要がある。加えて、TestKitに対してどのようにtestデータベースへ接続するのか、テーブルのリストをどのように取得するのか、テスト間におけるクリーンをどのようにして行うのかなどといった事を表すTestDBの実装が必要になる。
PostgreSQLのテストハーネスの場合(src/test/slick/driver/test/MyPostgresTest.scala)、大抵のデフォルト実装は、そのままですぐに使える用になっている。localTablesとgetLocalSequencesのみ、カスタマイズした実装が必要になる。JDBCのgetFunctions呼び出しをサポートしないドライバである事を明示するために、ドライバのcapabilitiesを変更する。
@RunWith(classOf[Testkit])
class MyPostgresTest extends DriverTest(MyPostgresTest.tdb)
object MyPostgresTest {
def tdb = new ExternalJdbcTestDB("mypostgres") {
val driver = MyPostgresDriver
override def localTables(implicit ec: ExecutionContext): DBIO[Vector[String]] =
ResultSetAction[(String,String,String, String)](_.conn.getMetaData().getTables("", "public", null, null)).map { ts =>
ts.filter(_._4.toUpperCase == "TABLE").map(_._3).sorted
}
override def getLocalSequences(implicit session: profile.Backend#Session) = {
val tables = ResultSetInvoker[(String,String,String, String)](_.conn.getMetaData().getTables("", "public", null, null))
tables.buildColl[List].filter(_._4.toUpperCase == "SEQUENCE").map(_._3).sorted
}
override def capabilities = super.capabilities - TestDB.capabilities.jdbcMetaGetFunctions
}
}
設定のプレフィックス名(上記例ではmypostgres)はExternalJdbcTestDBへ渡してあげる必要がある。
def tdb =
new ExternalJdbcTestDB("mypostgres") ...
Database Configuration
PostgreSQLのテストハーネスはExternalJdbcTestDBをベースにしているため、test-dbs/testkit.confの設定をいじる必要がある。
mypostgres.enabled = true
mypostgres.user = myuser
mypostgres.password = secret
ExternalJdbcTestDBを扱うためのオプショナルな設定が他にもいくつかある。testkit-reference.confには、適切なデフォルト値が設定されており、testkit.confをシンプルに保つのが良い。
Testing
sbt test を実行すると、 MyPostgresTest を探索し、TestKitのJUnit runnerを用いて実行される。これはテストハーネスを通してセットアップされたデータベースを用いており、ドライバを用いて適応可能な全てのテストが実行される事になる。
