Slick 3.0.0 documentation - 11 Coming from ORM to Slick
Permalink to Coming from ORM to Slick — Slick 3.0.0 documentation
ORMからSlickを利用する人へ
Introduction
Slickは、Hibernateや他のJPAベースのプロダクトのようなORM(object-relational mapper)では無い。SlickはORMのようにデータを永続化させるソリューションの1つであり、いくつかのコンセプトは共有しつつも、大きな違いがいくつかある。本章ではSlickのメリットについての理解を手助けしつつ、ORMとの違いについて順に説明する。object-relationalなものに対して言及される様々な問題(object-relation-impedance mismatch)をSlickは上手く取り扱っていることについても説明したい。
SlickはFRM(functional-relational mapper)である、と表現されるのが良い。Slickはイミュータブルなコレクションをもとにして関係データを取り扱っており、より自由なクエリ生成とうまくコントロールされた副作用処理に対し、特に焦点を当てた作りになっている。ORMでは一般的にミュータブルなオブジェクトグラフをむき出しにし、read-・write-cachesのような副作用や、ハードコードサポート(継承を利用したユースケースや関連テーブルを通した関連の取得など)を利用してしまっている事が多い。ORMではオブジェクトグラフの永続化に焦点を当てている一方、Slickは関連データストアにアクセスする最も良い方法に焦点を当てている。
ORMはオブジェクト指向言語からデータベースを利用する際には、自然なアプローチをとっている。ORMではデータがメモリ内に残っていたとしても、オブジェクトグラフを部分的に永続化させようとする。オブジェクトは編集可能、関連も変更が可能であり、オブジェクトグラフは色々と状態が変化する。実のところ、このようなものに対して正確に保存をするのは簡単ではない。それゆえこの問題を object-relation impedance mismatchと呼んでいる。これはORMの実装をを難しくさせている所以であり、ほんの少し難しいケースに対しても複雑化してしまうこともある。一方でSlickはオブジェクトグラフをむき出しにしたりはしていない。SlickはSQLや関連モデルからインスパイアされているし、型安全なScalaの特徴を利用しつつも、大抵の場合コンセプトはだいたい同じものになっている。データベースクエリはScalaの制限されたイミュータブルな、純粋関数のサブセットを用いて表現されている。Scala側からも代わりのものとしてfirst-class SQL supportを提供している。
実のところ、ORMはそれ自体が挑戦しようと試みている事に対する概念的な課題にしばしば直面する。これはORMが複雑なせいであり、実装上の課題であったり、使用上の課題であったりもする。以下では、ORMについての特徴と、なぜ代わりにSlickを用いる事を推奨するのかについて述べる。初めに、どのようにしてオブジェクトグラフとうまく付き合っていくかについて説明し、それからSlickがどのようにして取り組んでいるかをその特徴とユースケースを主に述べていく。
Configuration
いくつかのORMでは外部の設定ファイルを用いる。Slickは少しのScalaのコードを用いて設定を行う。データベースに接続する方法についての情報をSlickに提供し、Slickにクエリに対する型チェックを行いたいのならば、database-schemaを手で書くor自動生成させる。外部キーを用いる関連の定義といったようなものも、再利用可能な抽象メソッドを利用しつつ、基本的なScalaのコードで記述する事が出来る。
Mapping configuration.
以下の例では、このようなデータベーススキーマを用いる。
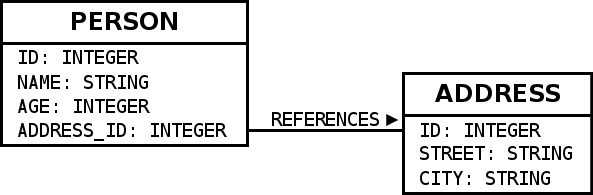
このスキーマをSlickで利用する際は、以下のようなコードを記述すれば良い。
type Person = (Int,String,Int,Int)
class People(tag: Tag) extends Table[Person](tag, "PERSON") {
def id = column[Int]("ID", O.PrimaryKey, O.AutoInc)
def name = column[String]("NAME")
def age = column[Int]("AGE")
def addressId = column[Int]("ADDRESS_ID")
def * = (id,name,age,addressId)
def address = foreignKey("ADDRESS",addressId,addresses)(_.id)
}
lazy val people = TableQuery[People]
...
type Address = (Int,String,String)
class Addresses(tag: Tag) extends Table[Address](tag, "ADDRESS") {
def id = column[Int]("ID", O.PrimaryKey, O.AutoInc)
def street = column[String]("STREET")
def city = column[String]("CITY")
def * = (id,street,city)
}
lazy val addresses = TableQuery[Addresses]
テーブルはケースクラスにマッピングされる。このコードは自動生成しても手で書いても良い。
ORMではコンフィグファイルの中でマッピングの仕様について記述を行う。Slickでは、上記の例のようにScalaの型として仕様を提供してあげる事ができ、型安全なSlickのクエリを用いる事ができる。違いとして、Slickのマッピングは概念上非常にシンプルだ。単にテーブルの情報を記述するだけでよく、列に対するマッピングを行うケースクラスやその他のファクトリや抽出子はオプショナルにすぎない。外部キーの情報は持たせる事が出来るものの、関連やその類の情報については保持しない。その代わりに再利用可能な部分的なクエリを用いたマッピングなども行える。
Navigating the object graph
Using plain old method calls
本章では、厳格vs遅延、もしくは義務的or宣言的について考えていきたい。一般的なORMの特徴の一つとして、オブジェクトグラフが、まるでメモリ上に存在しているかのように扱える、ということがある。関連メンバのような関連するオブジェクトについては、必要に応じてアドホックにデータがデータベースから読み込まれる。メモリ上にあるかのように表現するために、ORMは関連メンバに対する呼び出しを途中でフックしたりして、必要なデータを得るために、データベースクエリをその途中で実行したりしている。以下のORMっぽい例を見てみよう。
val people: Seq[Person] = PeopleFinder.getByIds(Seq(2,99,17,234))
val addresses: Seq[Address] = people.map(_.address)
データを取得するのに何回データベースとやり取りをする必要があるのだろうか?実際ORMのコレクション風APIを学ぶ際には、この質問に何度も直面することになるだろう。普通に考えると、このORMはgetByIdsの際にデータベースと一度やり取りを行い、Personに関する結果を返す。それからScalaのListのメソッドであるmapを使い、各Personからaddressを取得するために.map(_.address)を呼ぶ。ORMはこのmapのループの前にaddressが何度も呼ばれる事を通常知らない。その結果、各Personのaddressを取得するために何度もデータベースとやり取りをしなくてはならなくなるし、データベースのやり取りのコストを考えると、非常に非効率である(n+1問題)。この問題を解決するためには、以下の例のように、ORMに将来的にデータが必要になる旨を事前に伝えてあげることで、複数回のデータベース呼び出しを集約により効率化させる事ができる。
// 関連する`address`をロードしておくことをORMに事前に伝える
val people: Seq[Person] = PeopleFinder.getByIds(Seq(2,99,17,234)).prefetch(_.address)
val addresses: Seq[Address] = people.map(_.address)
ここでは仮のORMの中でprefetchメソッドにより各Personのaddressを予めロードしている。結果、データベースとのやり取りは1度か2度に収まる。addressの情報はORMの管理下にキャッシュされる。続く.map(_.address)では、キャッシュされたメモリ上の値からデータを得る事ができる。もちろんこれは2度もaddressへのマッピングを教えてあげる必要があるため無駄があるし、もしprefetchを忘れた場合には、非効率な処理になってしまうだろう。ORMにもよるが、prefetchの方法として外部の設定を用いるか、上記の例のようにインラインで記述する方法がある。
Slickは関連するデータを取得するのに異なる方法をとっている。同じような処理には、以下のような記述を行う。型アノテーションは必要無いが、分かりやすさのためにここでは記述している。
val peopleQuery: Query[People,Person,Seq] = people.filter(_.id inSet(Set(2,99,17,234)))
val addressesQuery: Query[Addresses,Address,Seq] = peopleQuery.flatMap(_.address)
見ての通り、この例はまさにScalaのコレクション操作と同じであり、違いは返り値がQuery型になるだけだ。この時点ではSlickは、データを取得する上で必要になるSQLを作るために必要な計画を練っているだけで、データベースに対しアクセスは行わない。上記の例は、まだ一度もデータベースにはアクセスしていない。実際にデータを取得するには、.resultを用いてdatabase Actionにクエリをコンパイルさせ、Databaseオブジェクトにrunしてもらう。
val addressesAction: DBIO[Seq[Address]] = addressesQuery.result
val addresses: Future[Seq[Address]] = db.run(addressesAction)
結果の取得には、たった1つのクエリのみが実行される。これはデータベースへのアクセスを行う箇所を明らかにしているし、非常に理に適っている。
Slickの例を見ての通り、Slickではオブジェクトグラフ(i.e. results)を直接操作したりはしない。その代わりにSlickは、データベースアクセス無しに効率的なクエリを発行出来るよう事前にクエリを組み立て、オブジェクトグラフを操作している。Slickでは実際に必要になるまでクエリの組立を遅延させ、Database.runの呼び出しによりクエリを発行させるのである。
ORMにおいてオブジェクトグラフを直接操作することは、あまりに早い状態でクエリを発行してしまうため問題になりやすい。そのためSlickではこのような機能を外した。ORMはこの問題に取り組むにあたり、しばしば宣言的なクエリ言語を用いて問題を解決しようとしている。これはSlickの動作とよく似たものになっている。
Query languages
ORMはしばしばJPAのSQLやCriteria APIのような宣言的なクエリ言語を用いている。SQLやSlickのように、これらのクエリ言語は実行すること無しにクエリを表現する事が可能であり、クエリを実行するには明示的な処理を必要とする。
String based embeddings
ここではHQLの例を出すが、一般的にこのようなクエリ言語では、SQLは文字列としてプログラムに埋め込まれている。HQLの例を見てみよう。
val hql: String = "FROM Person p WHERE p.id in (:ids)"
val q: Query = session.createQuery(hql)
q.setParameterList("ids", Array(2,99,17,234))
大抵の言語において、コンパイラを変更せずに任意の言語を埋め込むのには文字列を使うのが最も簡単である。シンプルである一方、この種の埋め込みには大きな制限がかかる。
1つの大きな問題としては、このようなツールには埋め込まれた言語や、任意の文字列としてクエリを扱う事に対する知識を持たせる事が出来ない。ホストされた言語のコンパイラやインタプリタは記述の間違いを発見したりは出来ないし、もしクエリが期待する型とは異なる型を返しても間違いを検出出来ない。1つの解決法としては、IDEによりシンタックスハイライトやコード補完、インラインのエラーなどを表示させる、といった方法があげられる。
また、大きな問題として、この種の言語では再利用が難しい。クエリの一部分を再利用するために文字列を結合したいと考えるかもしれない。上記のHQLの例で、idによるフィルタリングの機能を再利用可能なものとして扱いたいとする。Personテーブル以外にもAddressテーブルでその機能を使いたくても、これは非常に扱うのが難しいものになってしまう。
Javaはその他多くの言語において、文字列は正確なクエリ言語を埋め込む唯一の方法になっている。次のセクションを見て、Scalaがいかに柔軟かを確認して欲しい。
Method based APIs
埋め込み言語にとって柔軟性を得るものとして、その他のアプローチとして、ホストされた言語の拡張機能を用いて同様の機能を利用する方法があげられる。JavaやScalaのようなオブジェクト指向言語はオブジェクトやメソッドのAPI定義を通した拡張を許可している。JPAのCriteria APIはこの概念を利用しており、Slickも同様に利用している。これは埋め込まれた言語を部分的に理解するために、ホストされた言語の機能を利用している。Criteria Queriesを用いた例を見てみよう。
val id = Property.forName("id")
val q = session.createCriteria(classOf[Person])
.add( id in Array(2,99,17,234) )
埋め込みを利用するメソッドはクエリを部分的に利用可能なものへと変化させる。idによるフィルタリングのみの機能を生成するのも容易い。
def byIds(c: Criteria, ids: Array[Int]) = c.add( id in ids )
...
val c = byIds(
session.createCriteria(classOf[Person]),
Array(2,99,17,234)
)
もちろん上の例は取るに足らない例ではあるが、より複雑なクエリを合成する上で、このメソッドは既に役立つものになっている。
JPAのCriteria APIのようなJava APIは、Scalaのようにオペレータの機能をオーバーロードしたりは出来ない。これはクエリを表現する際のよく似たコードを減らす。例として、5歳より若いか65歳より歳のいった人を取得するクエリを考えてみよう。
val age = Property.forName("age")
val q = session.createCriteria(classOf[Person])
.add(
Restrictions.disjunction
.add(age lt 5)
.add(age gt 65)
)
Scalaはオペレータをオーバーロード出来るため、Slickでは以下のような記述が可能になり、クエリはより簡潔なものになる。
val q = people.filter(p => p.age < 5 || p.age > 65)
Scalaのオーバーロードには、Slickにも影響を与えるものとして、いくつか制限があった。Slickでは、クエリの中で==は===に、!=は=!=と記述しなくてはならない。また、文字列結合にも+の代わりに++を用いなくてはならない。さらに、ifという予約後をオーバーロードする事も出来ない。Slickでは代わりのものとして、DSL for SQL case expressionsを提供している。
前述した通り、Slickでは、クエリを実行しないクエリを記述するためだけのものとして、プレースホルダ構文も扱える。以下の例では分かりやすさのために型アノテーションを書いているが、実際には書く必要はない。
val q = (people: Query[People, Person, Seq]).filter(
(p: People) =>
(
((p.age: Rep[Int]) < 5 || p.age > 65)
: Rep[Boolean]
)
)
Queryはコレクション風のクエリ表現を指定する。PeopleはPersonのテーブルのために定義されたSlickのTableのサブクラスである。値が列を表すプロトタイプとして用いられることに混乱してしまうかもしれない。個々のカラムを表すRepのメンバーもある。filterをするために、いくつかのRep[Int]を用いてRep[Boolean]を得ている。内部的にSlickは、オペレーション内容を表すSQLコードを生成するのに用いられるツリーを作成している。Slickはしばしばこのような表現木(持ち上げられた表現として、プレースホルダーの値を含んだもの)の生成プロセスを呼び出す。これ故にSlickのクエリインターフェスの1つを lifted embedding と呼んでいる。
Scalaが型安全であるのは非常に重要な事である。例として、SlickはRep[String]のために.substringというメソッドをサポートしている(Rep[Int]には使えない)。これはJavaやCriteria QueriesのようなJava APIにおいては利用不可能なものである。Scalaでは暗黙的な表現を通したメソッド拡張に基づく型パラメータを利用する事で、サポートが可能となった。ScalaコンパイラのようなツールやIDEが、コードを正確に理解したりチェックやサポートを行ってくれるのを手助けしてくれる。
Slickのようなクエリ言語において、Scalaのコレクション操作のシンタックスシュガーであるfor式が非常に役立つ。上の例は、for式を使う事で、以下のように書き換える事が出来る。
for( p <- people if p.age < 5 || p.age > 65 ) yield p
Scalaのfor式は、SQLやORMのクエリ言語によく似たものになる。一方で、ソートやグルーピングのような幾つかの操作のためのシンタックスサポートが欠けている。
( for( p <- people if p.age < 5 || p.age > 65 ) yield p ).sortBy(_.name)
シンタックスの制限があるにも関わらず、for式は複数のinner joinを利用する時などに非常に便利なものとなる。
先に記述したような、Criteria QueriesのようなメソッドベースなクエリAPIの問題は、ORMのクエリ言語にある概念上の制限とは異なる事を胸に留めといて欲しい。ScalaのORMはSlickのようなクエリ言語にオファーしても良いし、そうすべきであると考えている。快適にクエリを合成出来る事は、コードの再利用性に大きなメリットをもたらす。これは多くの開発者にとってSlickのお気に入りの機能になるのではないだろうか。
Macro-based embeddings
Scalaのマクロは埋め込みクエリのためのもう一つのアプローチとなる。文字列として埋め込まれたクエリをコンパイル時にチェックすることが可能になる。QueryやRepに関わるSQLへのプレースホルダを使う事無しにScalaのコードを変換する事が可能になる。双方のアプローチはSlickで利用する事が出来るが、まだ万全の準備ができているわけではない。クエリ言語のためにマクロを用いているデータベースライブラリは他にも存在している。
Query granularity
ORMを用いると、データをロードする際にオブジェクトを取り扱ったり、最も小さい粒度として列を補完したりすることは凡そ亡くなる。これはフレームワークによって制限されているわけではないが、慣例としてそのように扱われている。Slickを用いると実際に欲しいデータのみを取得する事が簡単になる。Slickでは列をクラスに対してマッピング出来るが、そのような機能を使わないことでより効率的なクエリを実行出来る。その時その時に必要なデータのみを取り出すようなクエリを扱える。もしpersonの名前と年齢のみが必要なら、以下のようにする事でタプルを返すことができる。
people.map(p => (p.name, p.age))
このような記述により、正確に欲しいデータのみを取得することが可能になる。
Read caching
Slickはクエリの結果をキャッシュしない。Slickを扱うのは生のJDBCを扱う事と等しいようなもんだ。多くのORMではキャッシュの読み書きを行う。キャッシュは一種の副作用である。これらは、時に理解を難しくさせる。キャッシュにより保存されたデータとそのライフタイムを扱う事は難しい。
PeopleFinder.getById(5)
ORMの例においては、ここではデータベースもしくはキャッシュから値を取り出している。どのような処理が生じたのかが明らかになっていない。Slickではデータベースとのやり取りは、クエリを実行させる処理を呼び出す必要があるので、非常に明確だ。Slickはオブジェクトへのアクセスに干渉したりもしない。
db.run(people.filter(_.id === 5).result)
Slickは毎度データベースのデータに対して、矛盾のないイミュータブルなスナップショットを返す。もし複数クエリに対する永続性を保証したいのなら、トランザクションを用いれば良い。
Writes (and caching)
多くのORMでは書き込み操作はパフォーマンスのためにキャッシュを経由する。
val person = PeopleFinder.getById(5)
person.name = "C. Vogt"
person.age = 12345
session.save
上の仮ORMのレコードは、オブジェクトを変更し、.saveメソッドを呼ぶことでデータベースとのやり取りを1度だけ行いデータを同期させている。Slickでは以下のような記述が可能だ。
val personQuery = people.filter(_.id === 5)
personQuery.map(p => (p.name,p.age)).update("C. Vogt", 12345)
Slickは宣言的な変換を内包してしまっている。オブジェクトの個々の値を順に変更するのではなく、全ての変更を同時に行い、キャッシュを通さずにデータベースとのやり取りを1度だけ行う。Slickの新規ユーザにとって、このシンタックスは混乱を招くかもしれない。しかし実際にはこれはよく整理されたシンタックスになっている。Slickはクエリの選択、挿入、更新、削除に対するシンタックスを一体化している。上記personQueryはデータを取得するために単なる選択用クエリに過ぎない。実際には、クエリにより特定されたカラムの更新を行うためにこの選択用クエリは用いられる。personQueryは列の削除にもそのまま使える。
personQuery.delete // deletes person with id 5
データを挿入するには、代入するカラムを選択した後に、個々のカラムに対する値を挿入してあげたら良い。
people.map(p => (p.name,p.age)) += ("S. Zeiger", 54321)
Relationships
ORMは一対多関連、多対多関連に対しハードコードされたサポートを提供している。関連に関しては設定の中でセットアップが行われる。一方、SQLでは各クエリに対しjoinを用いる事で関連を取得する。joinを用いることで柔軟な記述が可能になる。Slickでは両方の記述方法をより良い形で提供している。SlickのクエリはSQLと同じぐらい柔軟であるのに加えて、組み合わせ可能なものになっている。join条件に関わる部分的なクエリを定義する事もできるため、言語レベルの抽象化が可能になる。Slickがこの種のユースケースのためにハードコードサポートする必要は全く無い。あなたは、一対多、多対多関連や複数テーブルを跨ぐ関連の取得に対しても、任意のユースケースに対して簡単に実装が行える。
PersonとAddressに対する例は以下のようになる。
implicit class PersonExtensions[C[_]](q: Query[People, Person, C]) {
// 住所に対する関連のマッピング
def withAddress = q.join(addresses).on(_.addressId === _.id)
}
...
val chrisQuery = people.filter(_.id === 2)
val stefanQuery = people.filter(_.id === 3)
...
val chrisWithAddress: Future[(Person, Address)] =
db.run(chrisQuery.withAddress.result.head)
val stefanWithAddress: Future[(Person, Address)] =
db.run(stefanQuery.withAddress.result.head)
Slickを初めて使うユーザがよくする質問として、どのようにして関連の結果を利用するのか、といったことがあげられる。ORMではおそらくこんな感じで書けるのだろう。
val chris: Person = PeopleFinder.getById(2)
val address: Address = chris.address
以前に説明したように、Slickはデータがメモリ上にあるかのようにオブジェクトグラフを操作出来るようにはしていない。関連を直接操作するのではなく、データベースにアクセスする前に、関連データを取得するような別のクエリを記述して欲しい。
val chrisQuery: Query[People,Person,Seq] = people.filter(_.id === 2)
val addressQuery: Query[Addresses,Address,Seq] = chrisQuery.withAddress.map(_._2)
val address = db.run(addressQuery.result.head)
上の例では型アノテーションを記述しているが、これは普段の記述には必要無く、取り除くことで見通しの良いコードになるだろう。そしてデータベースへのアクセスがどこで発生するのかについて非常に分かりやすいものになっている。
他のSlick初心者の中には、どのようにしたらSlickで以下のような記述が出来るのか、といった疑問を考える人もいるかもしれない。
case class Address( … )
case class Person( …, address: Address )
ここにはPersonがAddressを必要とすることがハードコードされてしまうという問題がある。そのような情報無しにデータが読み込まれてはならない。もしそのような挙動を許してしまったなら、正確にデータを読み込ませる事を上手くユーザの管理下に置かせるという、Slickの哲学に反するものになってしまう。1つのテーブルからタプルやケースクラスへのマッピングを定義しているが、関連オブジェクトへのリファレンスをオブジェクトに持たせる事はSlickでは行っていない。その代わりに、2つのテーブルを結合させ、それらの結果をタプルもしくは結果の合わさったケースクラスのインスタンスとして返すメソッドを記述することができる。これは関連を明示するだけものであり、クラスの1つに強く紐付いたものにはなっていない。
val tupledJoin: Query[(People,Addresses),(Person,Address), Seq]
= people join addresses on (_.addressId === _.id)
...
case class PersonWithAddress(person: Person, address: Address)
val caseClassJoinResults = db.run(tupledJoin.result).map(_.map(PersonWithAddress.tupled))
それ以外のアプローチとして、関連オブジェクトへの参照を表すOption型のメンバ変数をクラスに定義させることも出来る。Noneは関連オブジェクトがまだ読み込まれていない事を表す。しかしこれはタプルやケースクラスを用いても型安全性に欠けるものになっている。なぜなら、関連オブジェクトが読み込まれたとしても厳格なチェックが出来ないためである。
Modifying relationships
ORMを用いて関連を操作する際に、関連オブジェクトのミュータブルなコレクションを用いて挿入や削除を行うといったことがしばしば見受けられる。変更は即座にデータベースへ書き込まれる、もしくはキャッシュに記録された後にまとめて書き込まれる。ステートフルなキャッシュやミュータブルなオブジェクトを扱うのを避けるために、SlickはSQLのように外部キーを用いた関連操作を提供している。関連の変更は、単に普通のフィールドを変更するかのように、外部キーのフィールドを新しいidへ更新する事で行う。良いことに、これはメモリにロードされていないオブジェクトの関連を、作成したり取り除いたりも出来るようになっている。単にidを扱うだけで十分なのである。
Inheritance
Slickは任意のオブジェクトグラフを押し付けたりはしない。Scalaに統合されたナイスな関連データモデルを提供しているだけである。関連スキーマは継承を含んでたりはしない。一般的に継承は、ルールに沿うような関連に簡単に取って代わられる。fooはbarであるというのは、barという役割を持つfooを考えるのと同じである。Slickはクエリ合成やクエリの抽象化を許可しており、継承風のクエリスニペットを実装するのは容易いし、再利用のための関数にも用いやすい。Slickは枠外の機能を提供していないが、その柔軟さゆえにあなた自身のコードの中で問題に合うような記述法等を自由に記述しても良い。
Code-generation
上記のようなコンセプトの多くは、Scalaのコードを用いてコードの重複を避けるような抽象化が行われる。しかし、もしかするとあなたはScalaの型システムの抽象能力の限界に達してしまうかもしれない。コード生成はこの課題に対する解決法の1つとして提供されている。Slickは非常に柔軟で様々なカスタマイズも行えるcode generatorを提供している。コード生成機能はデータベースのメタデータを用いて動作する。Slickの型、関連情報を生成するのに必要な独自のメタデータを組み合わせる事も出来る。詳しくはScala Days 2014のトークを見て欲しい。
