Slick 3.0.0 documentation - 12 Coming from SQL to Slick
Permalink to Coming from SQL to Slick — Slick 3.0.0 documentation
SQLからSlickを利用する人へ
JDBC/SQLを利用していて、Slickに移ってきた場合には躓くことなく学ぶ事が出来るだろう。Slickはコネクションハンドリング、結果の取得、クエリ言語の利用という事についてより良いAPIを備えている。さらに文字列クエリを書くよりも、Scalaを通してより良い記述が行えるようなものを統合している。SQLを知っていてSlickを学ぼうと考えている開発者にとっての主な障壁は、SQLとScalaのコレクションの間にある、よく似た操作に対するセマンティックの違いのみであろう。本章ではこれらの違いについての概要をみていく。概念的な違いを考えた後に、SQL操作とSlickの操作の比較を例を通して説明していく。SlickのAPIに関する詳細な説明については、クエリについての章やthe Scala collections APIにあるメソッドを見て欲しい。
Schema
本章ではこのようなデータベーススキーマを例に説明を行う。
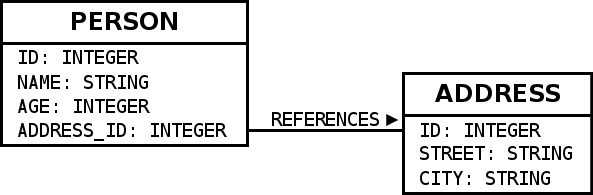
Slickで上記スキーマを記述した際には、以下のように定義出来る。
type Person = (Int,String,Int,Int)
class People(tag: Tag) extends Table[Person](tag, "PERSON") {
def id = column[Int]("ID", O.PrimaryKey, O.AutoInc)
def name = column[String]("NAME")
def age = column[Int]("AGE")
def addressId = column[Int]("ADDRESS_ID")
def * = (id,name,age,addressId)
def address = foreignKey("ADDRESS",addressId,addresses)(_.id)
}
lazy val people = TableQuery[People]
...
type Address = (Int,String,String)
class Addresses(tag: Tag) extends Table[Address](tag, "ADDRESS") {
def id = column[Int]("ID", O.PrimaryKey, O.AutoInc)
def street = column[String]("STREET")
def city = column[String]("CITY")
def * = (id,street,city)
}
lazy val addresses = TableQuery[Addresses]
テーブルはケースクラスにマッピングされる。このコードは自動生成しても手で書いても良い。
Queries in comparison
JDBC Query
エラーハンドリングを伴うJDBCのクエリはこのように書ける。
import java.sql._
Class.forName("org.h2.Driver")
val conn = DriverManager.getConnection("jdbc:h2:mem:test1")
val people = new scala.collection.mutable.MutableList[(Int,String,Int)]()
try{
val stmt = conn.createStatement()
try{
val rs = stmt.executeQuery("select ID, NAME, AGE from PERSON")
try{
while(rs.next()){
people += ((rs.getInt(1), rs.getString(2), rs.getInt(3)))
}
}finally{
rs.close()
}
}finally{
stmt.close()
}
}finally{
conn.close()
}
Slickはクエリを記述するのに2つの方法を提供してくれている。1つはJDBCのようにSQL文字列をそのまま書くこと、もう1つの方法は型安全で合成可能なクエリを記述する事である。
Slick Plain SQL queries
もしSQLを用いてクエリを書き続けたい、もしくはSlickにまだサポートされていない機能が必要なら、SlickのPlain SQLクエリが役立つ。SlickのPlain SQLを用いて上記の例と同様のクエリを記述すると、以下のようになる。この中にはエラーハンドリングや、非同期実行のために最適化されたリソース管理機能などが含まれている。
import slick.driver.H2Driver.api._
...
val db = Database.forConfig("h2mem1")
...
val action = sql"select ID, NAME, AGE from PERSON".as[(Int,String,Int)]
db.run(action)
.listは結果のリストを返し、.headは結果を1つだけ貸す。.foreachは全ての結果を1度だけイテレートさせて取り扱うのに用いられる。
Slick type-safe, composable queries
Slickの重要な機能の1つとして、型安全で合成可能なクエリがある。SlickはScalaからSQLへ変換するためののコンパイラを持っている。基本的なライブラリのサブセットやいくつかの拡張についても利用可能である。Scala開発者はSQLについて知らなくても少しの基本的学習と特定の方言について覚えるだけで、関連データベースに対する多くのクエリを即座に記述する事が出来るようになる。Slickのクエリは合成可能である。これはSQL文字列を結合するかのような、joinに関する条件式であるとか、そのような繰り返し利用されるコードの重複を避けるための再利用可能な部分クエリを記述出来る事を表す。そのようなクエリは型安全であり、コンパイル時に間違いを発見出来るのみならず、SQLインジェクションのリスクをなくす事が出来る。
型安全なSlickによるクエリは、上記JDBCの例と同じサンプルに対して、以下のように記述出来る。
import slick.driver.H2Driver.api._
...
val db = Database.forConfig("h2mem1")
...
val query = people.map(p => (p.id,p.name,p.age))
db.run(query.result)
.runは自動的にコレクション風のクエリにはSeqを、スカラ値に対するクエリには単一の結果を返す。.list、.head、.foreachも同様に利用できる。
SQL文字列利用する場合と比較して、メソッド呼び出しによりクエリを簡単に組み立てる事が出来る。例として、query.filter(_.age > 18)は結果を絞り込むようなクエリを返す。これにより、メンテナンスしやすい、再利用可能なクエリを作成する事ができる。joinに対する条件や、ページング、絞り込みなど、様々な抽象化が行える。
Slickはクエリの型チェックを行うための型情報を必要とすることに注意して欲しい。このような型情報は、データベーススキーマと強く紐付いていなくてはならず、上の方で記述したように、TableのサブクラスとTableQueryの値を定義してあげる必要がある。
Main obstacle: Semantic API differences
ScalaのコレクションのメソッドがSQLに備わっているものと少し異なる事がある。新しくSQLの知識を基にSlickを学ぼうと考えている人にとっては、少し障壁となってしまう可能性がある。特にgroupByはトリッキーなものに思えるだろう。
Slickの型安全なAPIを利用したクエリを記述するための最適なアプローチとして、Scalaのコレクションについて考えてみるのが良い。もしSlickのTableQueryオブジェクトの代わりに、タプルやケースクラスのSeqを扱う場合には、コードはどのようなものになっているだろうか。恐らく同じようなコードを記述する事になるだろう。もしScalaのライブラリの特徴がSlickによってサポートされていなかったり、少し異なるものになっている場合には、別途一時的に対応する必要がある。いくつかの操作に関しては、Scalaの場合よりSlickの場合の方が強い型情報を持つ事がある。違いの1つとして、算術演算には.asColumnOf[T]を用いた明示的なキャストを必要とする。またSlickはOption操作のために3つの値のロジックを用いている (Also Slick uses 3-valued logic for Option inference.)。
Scala-to-SQL compilation during runtime
Slickは型安全なクエリを提供するために、ScalaからSQLへ変換するためのコンパイラを持っている。このコンパイラはScalaのランタイムに実行され、複雑なクエリに対しては少しばかりの時間を必要とする。クエリが定義される度に1度だけコンパイラが実行されるのは、非常に役立つ。実行時に毎度行われる代わりに、アプリ起動時にコンパイルさせるなど。Compiled queriesを用いると、再利用のために生成されたSQLをキャッシュさせる事が出来る。
Limitations
Slickを大々的に使っている場合にいくつかのケースで、Slickの型安全なクエリ言語がクエリオペレータやJDBCの機能を一部サポートしていないために、最適化されてないSQLコードを使いたいといった要求があるかもしれない。これに対処する方法がいくつかある。
Missing query operators
Slickに対して、存在していないオペレータを追加してあげる事が出来る。
Definition in terms of others
Slickに既に存在するオペレータを用いて、何かしらの拡張を行いたい場合には、単にScalaのメソッドを書くか、存在するオペレータに対してメソッドを生やすような暗黙的クラスを書くと良い。以下の例では、squaredというメソッドを追加している。
implicit class MyStringColumnExtensions(i: Rep[Int]){
def squared = i * i
}
...
// usage:
people.map(p => p.age.squared)
Definition using a database function
もしスカラ値を操作するような基本的オペレータが必要なら、それも実装して拡張してあげたら良い。例えばSlickにはpowerというメソッドが無いが、データベースの関数にあるPOWERを呼び出すには、以下のようなマッピングを定義する。
val power = SimpleFunction.binary[Int,Int,Int]("POWER")
...
// usage:
people.map(p => power(p.age,2))
この部分に関する詳細な情報が欲しければ、Scalar database functionsを参考にして欲しい。
データベースの関数を利用するクエリを操作するオペレータを追加することは出来ない。これは、SlickのScalaからSQLへ変換するコンパイラが最もシンプルなSQLクエリへコンパイルしようとする際、クエリの構造についての知識を必要とするためである。ゆえに、今現在ではカスタムクエリオペレータを取り扱う事は出来ない(この制限をどうにかしようとするアイデアはいくつかあるが、もう少し調査が必要である)。そのようなオペレータの例として、MySQLのindexヒントなどがある。これはSlickの型安全なAPIではサポートすることができず、ユーザによって追加することも出来ない。もしそのようなオペレータを操作する必要がある場合には、SlickのPlain SQLを使ってクエリを書いて欲しい。もしそのオペレータの返り値が変わらないものである場合には、次章で説明する一時的な解決法を利用することが出来るかもしれない。
Non-optimal SQL code
SlickはSQLを生成する際、出来る限りシンプルなクエリを作成しようとする。このアルゴリズムは完璧なものにはなっておらず、目下良いものにしようと開発中である。生成されたクエリが、手で記述したものよりもより複雑なものになってしまうケースもある。オプティマイザやDBMSを通してもこのようなクエリは悪いパフォーマンスとなる場合もある。例えばSlickは時折不必要なサブクエリを生成する。MySQLの5.5以下の場合において、不必要なテーブルスキャンと利用されないインデックスを用いることがある。Slickの開発チームはクエリオプティマイザが最適化出来るようなより良いコードを生成できるように取り組んでいる。このような場合の対処法としては、最適なSQLコードを手で書いてしまうしかない。手で書いたものはSlickのPlain SQLを通して実行できるし、このようなハックを利用するのも良い。この例では、型安全なクエリの対してSQLのコードを取って替えてしまっている。
people.map(p => (p.id,p.name,p.age))
.result
// 手で書いたSQLを注入している (https://gist.github.com/cvogt/d9049c63fc395654c4b4)
.overrideSql("SELECT id, name, age FROM Person")
SQL vs. Slick examples
本節では、利用頻度の多いSQLクエリと同じ意味をなすSlickの型安全なクエリとを比較して順に見ていく。
SELECT *
SQL
sql"select * from PERSON".as[Person]
Slick
SlickでSELECT *という記述は、TableQueryのresultを指す。
people.result
SELECT
SQL
sql"""
select AGE, concat(concat(concat(NAME,' ('),ID),')')
from PERSON
""".as[(Int,String)]
Slick
SELECTによる射影は、Scalaのmapに相当する。カラムは同様のものを指せば良いし、カラムに対する関数操作はScalaにおける同様のオペレータを基本的にはそのまま用いる事ができる(ただし、文字列の結合には+ではなく++を用いる)。
people.map(p => (p.age, p.name ++ " (" ++ p.id.asColumnOf[String] ++ ")")).result
WHERE
SQL
sql"select * from PERSON where AGE >= 18 AND NAME = 'C. Vogt'".as[Person]
Slick
WHERE条件は、Scalaのfilterを用いれば良い。==は利用できず、===を代わりに用いなければならない。
people.filter(p => p.age >= 18 && p.name === "C. Vogt").result
ORDER BY
SQL
sql"select * from PERSON order by AGE asc, NAME".as[Person]
Slick
ORDER BYはScalaのsortByを利用する。複数カラムを用いたソートにはタプルを渡してあげる必要がある。Slickの.ascと.descメソッドも昇順・降順を選ぶのに利用出来る。複数回.sortBy呼び出しを行うのは、複数カラムに対してORDER BYのと同じ挙動にはならない。複数カラムを用いたORDER BYには、.sortByに1度だけタプルを渡して欲しい。
people.sortBy(p => (p.age.asc, p.name)).result
Aggregations (max, etc.)
SQL
sql"select max(AGE) from PERSON".as[Option[Int]].head
Slick
集約関数については、Scalaにもある同じようなコレクションの操作関数を用いる事ができる。SQLではカラムに対して集約関数を呼び出すが、Slickではコレクションに対し集約メソッドを呼び出す。結果は個々に実行され、スカラー値が返却される。maxのような集約関数はNULLが返る事があるため、SlickではOptionが返却される。
people.map(_.age).max.result
GROUP BY
SQLを利用していた人にとって理解しにくいものの1つが、SlickのgroupByである。なぜなら、これはSQLとSlickで異なるシグニチャになるためである。SQLのGROUP BYはグルーピングを行うkeyで、グループ内の全ての要素をもとにした集合を生成する操作を行うような挙動になる。SQLではグルーピングされたコレクションから1つの値を取得するための、avgのような集約関数を実行する事が必要になる。
SQL
sql"""
select ADDRESS_ID, AVG(AGE)
from PERSON
group by ADDRESS_ID
""".as[(Int,Option[Int])]
Slick
ScalaのgroupByでは、グルーピングを行うkeyをもとに、各グループを列のListを値とするMapを作成する。各々のカラムをコレクションに自動的に変換したりはしない。SQLで集約を行うような操作をするには、得られたグループから必要なカラムへマッピングする操作行うといったように、Scala側で操作を明示的に行わなくてはならない。
people.groupBy(p => p.addressId)
.map{ case (addressId, group) => (addressId, group.map(_.age).avg) }
.result
SQLではグループ化された値を集約させる必要がある。そのため、Slickでも同じことを明示的に行わなくてはならない。これはつまり、groupByを呼び出した際には、その後にmapを呼び出すか、もし呼び出さない場合には例外を吐いて失敗してしまう。Slickのグループ化のシンタックスはSQLのものより少しばかり複雑なのだ。
HAVING
SQL
sql"""
select ADDRESS_ID
from PERSON
group by ADDRESS_ID
having avg(AGE) > 50
""".as[Int]
Slick
SlickはWHEREとHAVINGに対して異なるメソッドを持っていない。HAVINGを実現するためには、ただgroupByの後にfilterを行えば良い(さらにその後にmapも必要)。
people.groupBy(p => p.addressId)
.map{ case (addressId, group) => (addressId, group.map(_.age).avg) }
.filter{ case (addressId, avgAge) => avgAge > 50 }
.map(_._1)
.result
Implicit inner joins
SQL
sql"""
select P.NAME, A.CITY
from PERSON P, ADDRESS A
where P.ADDRESS_ID = a.id
""".as[(String,String)]
Slick
SlickはflatMapとmap(つまりfor式)によって暗黙的joinを生成する。
people.flatMap(p =>
addresses.filter(a => p.addressId === a.id)
.map(a => (p.name, a.city))
).result
...
// for式で同じ記述をすると、以下のようになる
(for(p <- people;
a <- addresses if p.addressId === a.id
) yield (p.name, a.city)
).result
Explicit inner joins
SQL
sql"""
select P.NAME, A.CITY
from PERSON P
join ADDRESS A on P.ADDRESS_ID = a.id
""".as[(String,String)]
Slick
Slickで明示的joinを生成するには、以下のようなDSLで書ける。
(people join addresses on (_.addressId === _.id))
.map{ case (p, a) => (p.name, a.city) }.result
Outer joins (left/right/full)
SQL
sql"""
select P.NAME,A.CITY
from ADDRESS A
left join PERSON P on P.ADDRESS_ID = a.id
""".as[(Option[String],String)]
Slick
outer joinはSlickの明示的なjoin DSLを使って書ける。注意して欲しいのはouter joinのSQLを用いると、結合時にnullにならないカラムがnullになり得る事だ。これに対しSlickでは、結合時にはそのようなカラムはOptionを返すようにしている。これに関して、結合時にマッチしなかった列と、元々NULLが含まれていてマッチした列との区別をすることが出来るようになっており、SQL本来の機能より良いものになっている。
(addresses joinLeft people on (_.id === _.addressId))
.map{ case (a, p) => (p.map(_.name), a.city) }.result
Subquery
SQL
sql"""
select *
from PERSON P
where P.ID in (select ID
from ADDRESS
where CITY = 'New York City')
""".as[Person]
Slick
Slickのクエリが合成可能である。サブクエリは単に予め用意されたクエリを用いるだけで済む。
val address_ids = addresses.filter(_.city === "New York City").map(_.id)
people.filter(_.id in address_ids).result // <- run as one query
.inにはサブクエリを渡す。インメモリのScalaコレクションに対しては.inSetを用いる。
Scalar value subquery / custom function
SQL
sql"""
select * from PERSON P,
(select rand() * MAX(ID) as ID from PERSON) RAND_ID
where P.ID >= RAND_ID.ID
order by P.ID asc
limit 1
""".as[Person].head
Slick
このコードではuser-defined database functionで説明した、単一の値を計算して返す関数を用いたサブクエリの使い方を示している。
val rand = SimpleFunction.nullary[Double]("RAND")
...
val rndId = (people.map(_.id).max.asColumnOf[Double] * rand).asColumnOf[Int]
...
people.filter(_.id >= rndId)
.sortBy(_.id)
.result.head
insert
SQL
sqlu"""
insert into PERSON (NAME, AGE, ADDRESS_ID) values ('M Odersky', 12345, 1)
"""
Slick
SQLを学んでいた人から見ると、挿入操作は初めに驚くべきポイントの1つになると思う。なぜなら、SQLと違ってSlickでは挿入すべきカラムを選択したクエリを再利用させる事が出来るからである。基本的には初めに選択用のクエリを書き、挿入を実行するActionとして+=を呼び出す。一度に複数の列を挿入する際には、++=にSeqを渡す。auto incrementなカラムは自動的に無視される。forceInsertを用いると、auto incrementされたカラムへ直接値を挿入することが出来る。
people.map(p => (p.name, p.age, p.addressId)) += ("M Odersky",12345,1)
update
SQL
sqlu"""
update PERSON set NAME='M. Odersky', AGE=54321 where NAME='M Odersky'
"""
Slick
挿入時と同じように、更新操作も更新を行いたいデータをfilterなどを用いて選択した後に、.updateにより値を更新させる。
people.filter(_.name === "M Odersky")
.map(p => (p.name,p.age))
.update(("M. Odersky",54321))
delete
SQL
sqlu"""
delete PERSON where NAME='M. Odersky'
"""
Slick
こちらも挿入時と同じように、削除したいデータを選択した後に削除を行う。クエリの結果を得るためではなく、.deleteは選択された列を削除するActionを得るために用いられる。
people.filter(p => p.name === "M. Odersky")
.delete
CASE
SQL
sql"""
select
case
when ADDRESS_ID = 1 then 'A'
when ADDRESS_ID = 2 then 'B'
end
from PERSON P
""".as[Option[String]]
Slick
SlickではCASEのための、小さなDSLを用意している。
people.map(p =>
Case
If(p.addressId === 1) Then "A"
If(p.addressId === 2) Then "B"
).result
